I think we have talked before about how pgbench is overly subject to
row update contention at small scale factors. Since every transaction
wants to update one (randomly selected) row of the "branches" table,
and since the number of branches rows is equal to the scale factor,
there is certain to be update contention when the number of clients
approaches or exceeds the scale factor. Even worse, since each update
creates another dead row, small scale factors mean that there will be
many dead rows for each branch ID, slowing both updates and index
uniqueness checks.
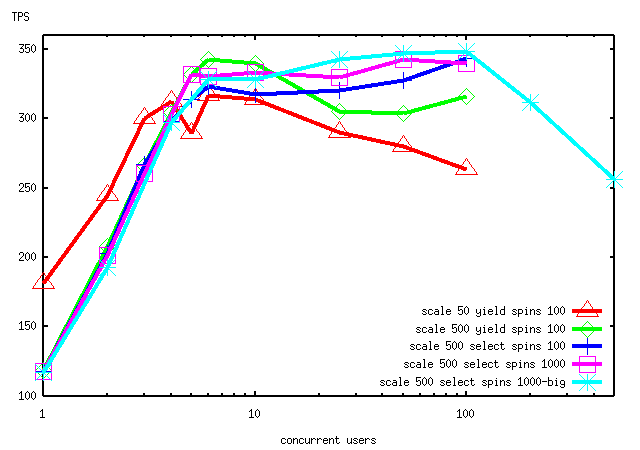
I have now carried out a set of test runs that I think illustrate
this point. I used scale factor 500 (creating an 8Gb database)
to compare to the scale-factor-50 results I got yesterday. Other
test conditions were the same as described in my recent messages
(this is a Linux 4-way SMP machine). In the attached graph, the
red line is the best performance I was able to get in the scale-
factor-50 case. The green line is the scale-factor-500 results
for exactly the same conditions. Although the speed is worse
for small numbers of clients (probably because of the larger
amount of work done to deal with a ten-times-larger database),
the scale-500 results are better for five or more clients.
What's really interesting is that in the scale-500 regime, releasing the
processor with sched_yield() is *not* visibly better than releasing it
with select(). Indeed, select() with SPINS_PER_DELAY=1000 seems the
best overall performance choice for this example. However the absolute
difference between the different spinlock algorithms is quite a bit less
than before. I believe this is because there are fewer spinlock
acquisitions and less spinlock contention, primarily due to fewer
heap_fetches for dead tuples (each branches row should have only about
1/10th as many dead tuples in the larger database, due to fewer updates
per branch with the total number of transactions remaining the same).
The last line on the chart (marked "big") was run with -N 500 -B 3000
instead of the -N 100 -B 3800 parameters I've used for the other lines.
(I had to reduce -B to stay within shmmax 32Mb. Doesn't seem to have
hurt any, though.) I think comparing this to the scale-50 line
demonstrates fairly conclusively that the tailoff in performance is
associated with number-of-clients approaching scale factor, and not to
any inherent problem with lots of clients. It appears that a scale
factor less than five times the peak number of clients introduces enough
dead-tuple and row-contention overhead to affect the results.
Based on these results I think that the spinlock and LWLock performance
issues we have been discussing are not really as significant for
real-world use as they appear when running pgbench with a small scale
factor. My inclination right now is to commit the second variant of
my LWLock patch, leave spinlock spinning where it is, and call it a
day for 7.2. We can always revisit this stuff again in future
development cycles.
regards, tom lane
{kind=link}