Re: GIN improvements part2: fast scan - Mailing list pgsql-hackers
| From | Tomas Vondra |
|---|---|
| Subject | Re: GIN improvements part2: fast scan |
| Date | |
| Msg-id | 52EEF472.9020106@fuzzy.cz Whole thread Raw |
| In response to | Re: GIN improvements part2: fast scan (Tomas Vondra <tv@fuzzy.cz>) |
| Responses |
Re: GIN improvements part2: fast scan
Re: GIN improvements part2: fast scan |
| List | pgsql-hackers |
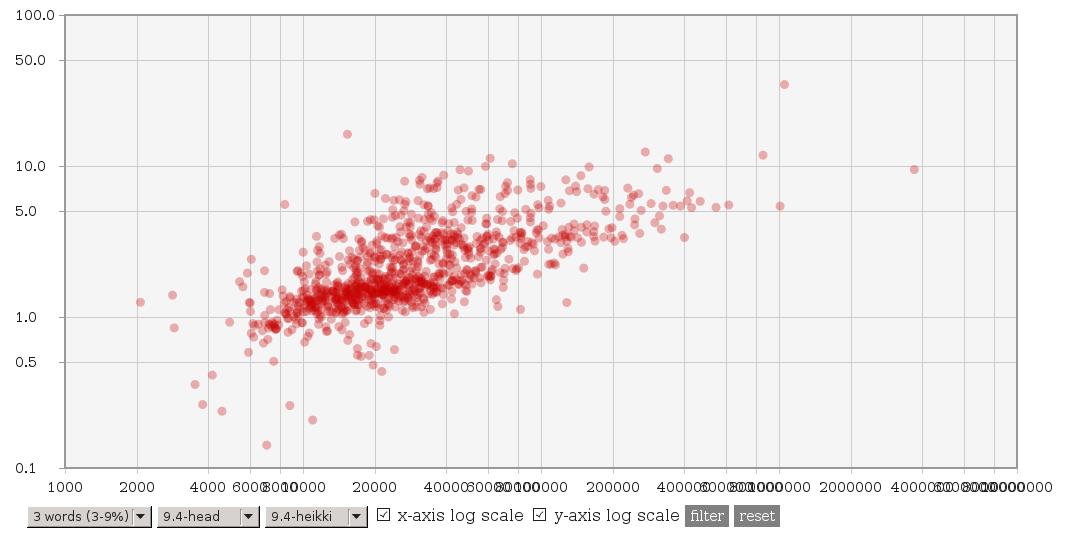
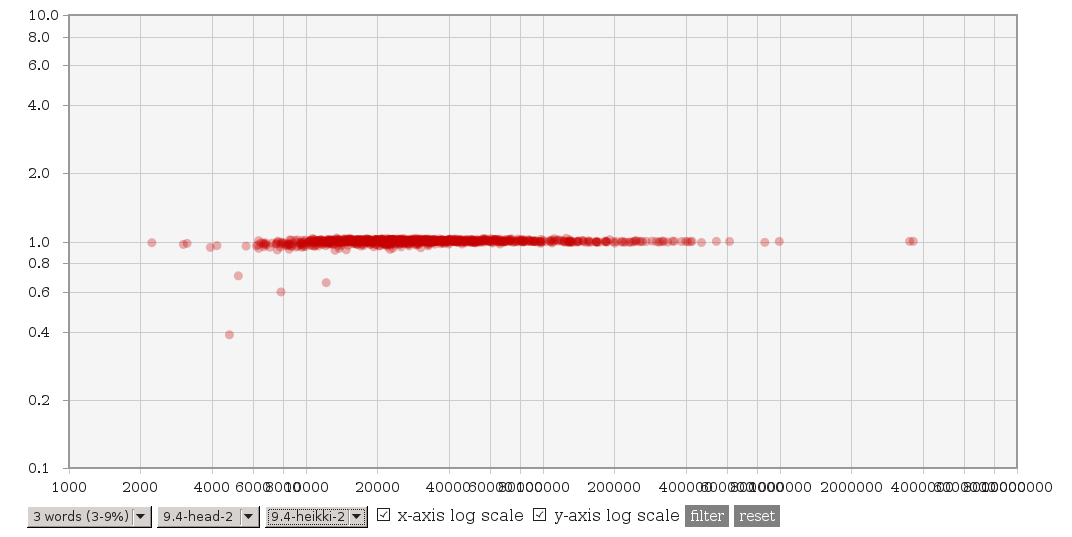
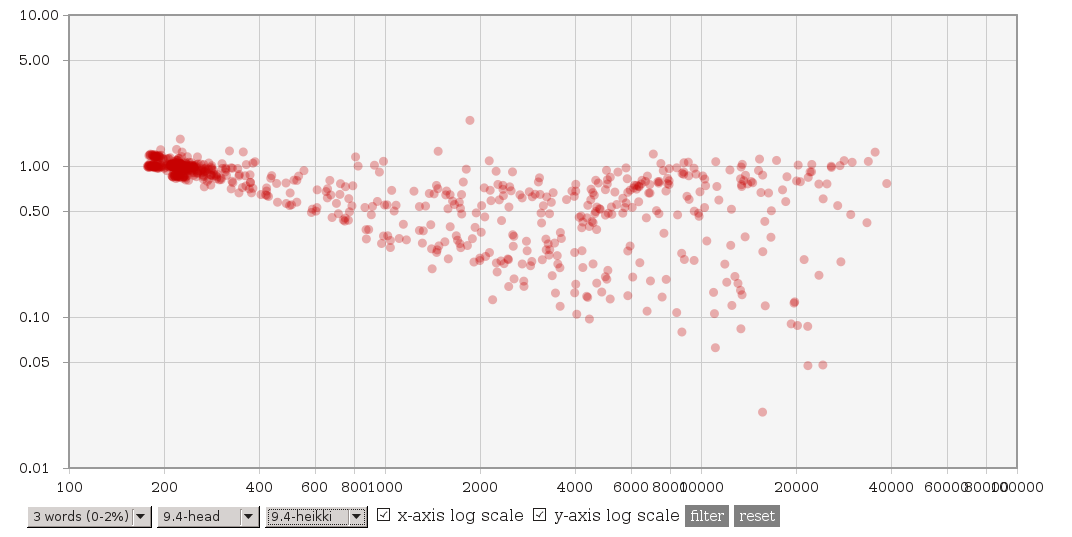
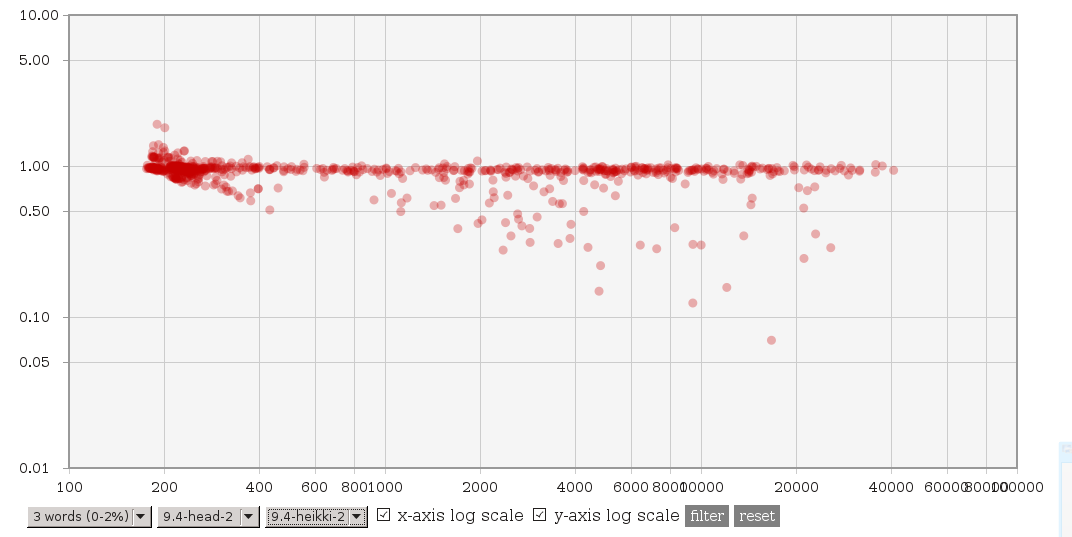
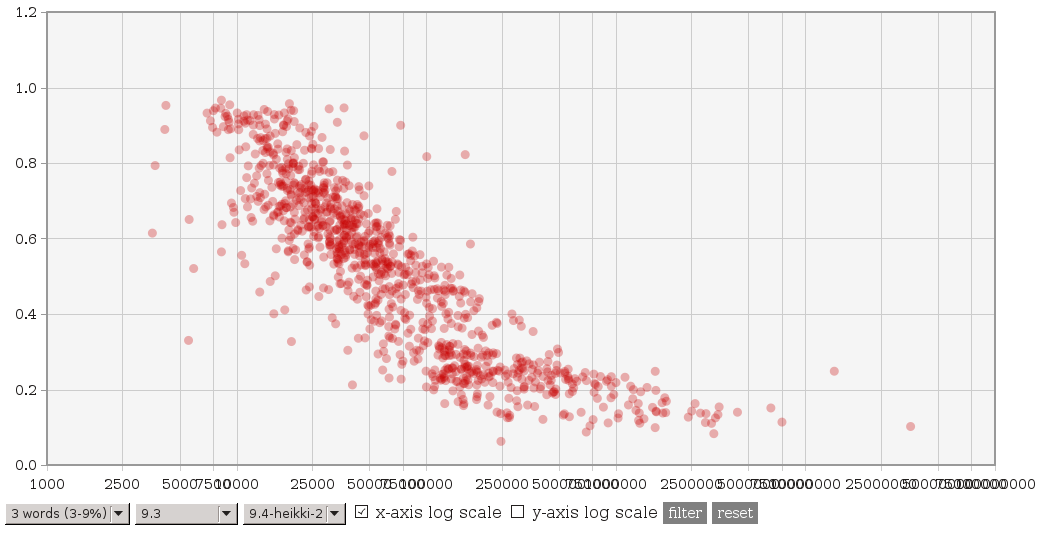
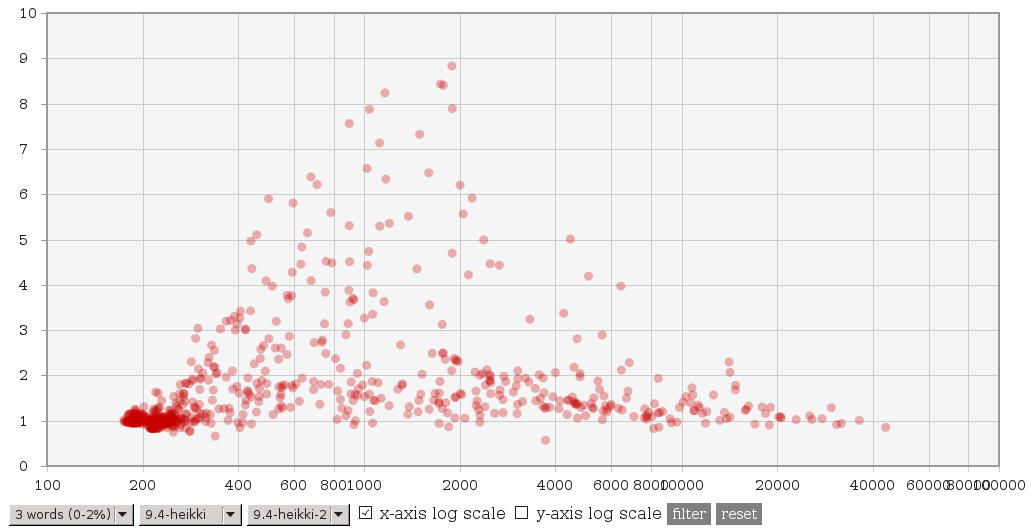
On 3.2.2014 00:13, Tomas Vondra wrote: > On 2.2.2014 11:45, Heikki Linnakangas wrote: >> On 01/30/2014 01:53 AM, Tomas Vondra wrote: >>> (3) A file with explain plans for 4 queries suffering ~2x slowdown, >>> and explain plans with 9.4 master and Heikki's patches is available >>> here: >>> >>> http://www.fuzzy.cz/tmp/gin/queries.txt >>> >>> All the queries have 6 common words, and the explain plans look >>> just fine to me - exactly like the plans for other queries. >>> >>> Two things now caught my eye. First some of these queries actually >>> have words repeated - either exactly like "database & database" or >>> in negated form like "!anything & anything". Second, while >>> generating the queries, I use "dumb" frequency, where only exact >>> matches count. I.e. "write != written" etc. But the actual number >>> of hits may be much higher - for example "write" matches exactly >>> just 5% documents, but using @@ it matches more than 20%. >>> >>> I don't know if that's the actual cause though. >> >> Ok, here's another variant of these patches. Compared to git master, it >> does three things: >> >> 1. It adds the concept of ternary consistent function internally, but no >> catalog changes. It's implemented by calling the regular boolean >> consistent function "both ways". >> >> 2. Use a binary heap to get the "next" item from the entries in a scan. >> I'm pretty sure this makes sense, because arguably it makes the code >> more readable, and reduces the number of item pointer comparisons >> significantly for queries with a lot of entries. >> >> 3. Only perform the pre-consistent check to try skipping entries, if we >> don't already have the next item from the entry loaded in the array. >> This is a tradeoff, you will lose some of the performance gain you might >> get from pre-consistent checks, but it also limits the performance loss >> you might get from doing useless pre-consistent checks. >> >> So taken together, I would expect this patch to make some of the >> performance gains less impressive, but also limit the loss we saw with >> some of the other patches. >> >> Tomas, could you run your test suite with this patch, please? > > Sure, will do. Do I get it right that this should be applied instead of > the four patches you've posted earlier? So, I was curious and did a basic testing - I've repeated the tests on current HEAD and 'HEAD with the new patch'. The complete data are available at [http://www.fuzzy.cz/tmp/gin/gin-scan-benchmarks.ods] and I've updated the charts at [http://www.fuzzy.cz/tmp/gin/] too. Look for branches named 9.4-head-2 and 9.4-heikki-2. To me it seems that: (1) The main issue was that with common words, it used to be much slower than HEAD (or 9.3). This seems to be fixed, i.e. it's not slower than before. See http://www.fuzzy.cz/tmp/gin/3-common-words.png (previous patch) http://www.fuzzy.cz/tmp/gin/3-common-words-new.png (new patch) for comparison vs. 9.4 HEAD. With the new patch there's no slowdown, which seems nice. Compared to 9.3 it looks like this: http://www.fuzzy.cz/tmp/gin/3-common-words-new-vs-93.png so there's a significant speedup (thanks to the modified layout). (2) The question is whether the new patch works fine on rare words. See this for comparison of the patches against HEAD: http://www.fuzzy.cz/tmp/gin/3-rare-words.png http://www.fuzzy.cz/tmp/gin/3-rare-words-new.png and this is the comparison of the two patches: http://www.fuzzy.cz/tmp/gin/patches-rare-words.png That seems fine to me - some queries are slower, but we're talking about queries taking 1 or 2 ms, so the measurement error is probably the main cause of the differences. (3) With higher numbers of frequent words, the differences (vs. HEAD or the previous patch) are not that dramatic as in (1) - the new patch is consistently by ~20% faster. Tomas
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: