On Wed, 3 Aug 2022 at 12:18, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> Hmm. My estimate of the percentages of users who will be pleased or
> not hasn't really changed since [2]. Also, realizing that you can't
> apply these aggregates to extremely large input sets, I wonder just how
> much it buys to be able to parallelize them. So I still put this patch
> in the category of "just because we can doesn't mean we should".
It's a shame you categorised it without testing the actual
performance. That's disappointingly unscientific.
Here's a quick benchmark to let you see what we might expect and how
it compares to the existing aggregate functions which can already be
parallelised:
create table ab (a int, b int);
insert into ab select x,y from
generate_series(1,1000)x,generate_Series(1,1000)y;
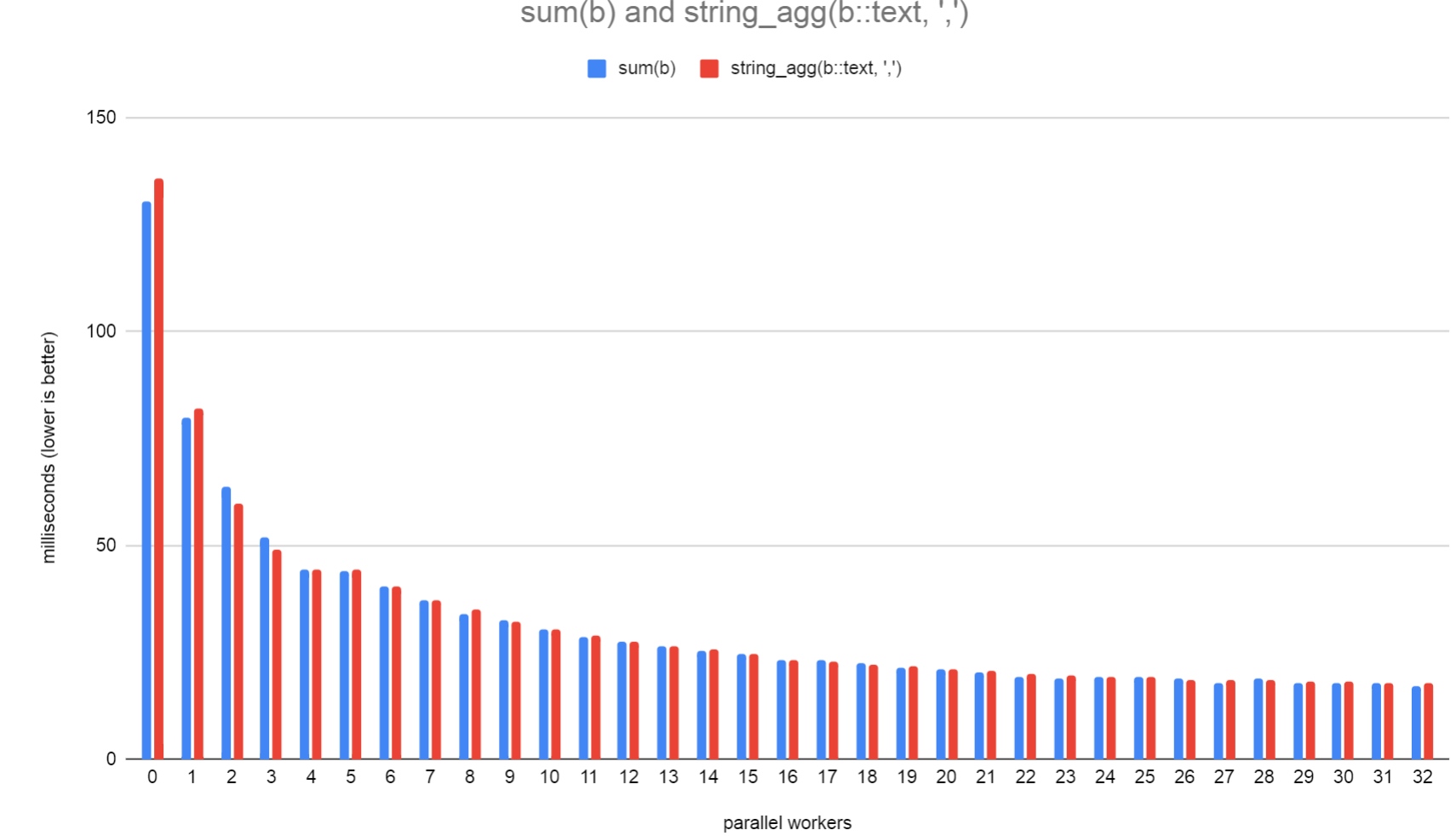
In the attached agg_comparison_milliseconds.png, you can see the time
it took to execute "select a,sum(b) from ab group by a;" and "select
a,string_agg(b::text,',') from ab group by a;". Both queries seem to
increase in performance roughly the same amount when adding additional
parallel workers.
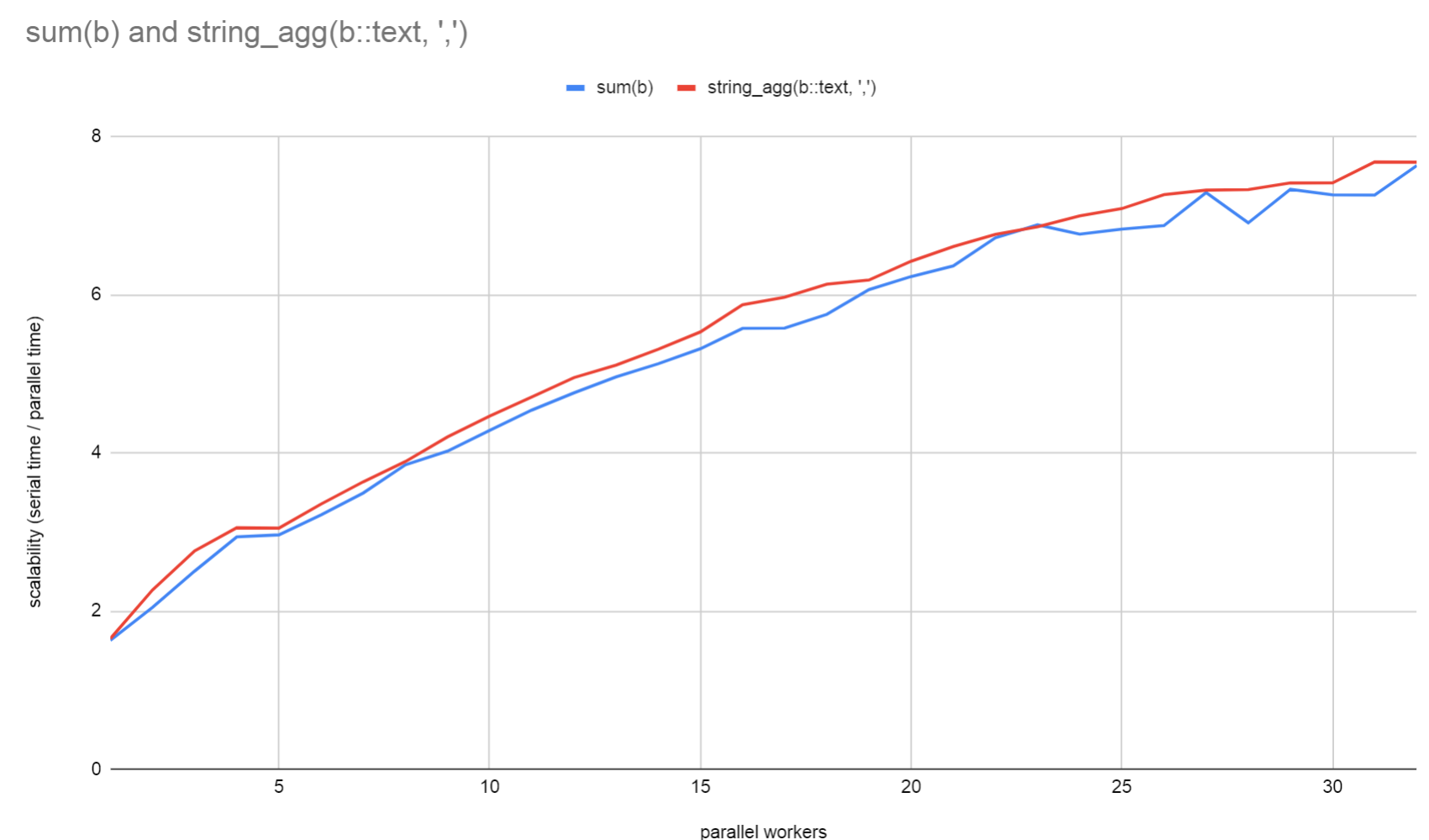
The attached agg_comparison_scalability.png shows the time it took to
execute the query with 0 workers divided by the time for N workers,
thus showing how many times the query was sped up with N workers. The
scalability of the string_agg() appears slightly better than the sum()
in this test due to the string_agg() query being slightly slower with
0 workers than the sum() version of the query. The sum query got 7.63x
faster with 32 workers whereas the string_agg query beat that slightly
with 7.67x faster than when the query was executed with parallelism
disabled.
I'd expect that scalability, especially the sum() version of the
query, to improve further with more rows.
Tested on an amd3990x machine with 64 cores / 128 threads.
> Now as against that, if the underlying relation scan is parallelized
> then you already have unpredictable input ordering and thus unpredictable
> aggregate results. So anyone who cares about that has already had
> to either disable parallelism or insert an ORDER BY somewhere, and
> either of those fixes will still work if the aggregates support
> parallelism.
I'm glad you're no longer worried about users skipping the ORDER BY to
increase performance and relying on luck for the input ordering.
I think, in addition to this now allowing parallel aggregation for
string_agg() and array_agg(), it's also important not to forget that
there are more reasons to have combine/serialize/deserialize functions
for all aggregates. Currently, a partition-wise aggregate can be
performed partially on the partition then if further grouping is
required at the top-level then we'll need the combine function to
perform the final grouping. No parallelism is required. Also, with
all the advancements that have been made in postgres_fdw of late, then
I imagine it surely can't be long until someone wants to invent some
syntax for requesting partially aggregated results at the SQL level.
It sure would be a shame if that worked for every aggregate but
string_agg and array_agg needed the foreign server to spit those
tuples out individually so that the aggregation could be performed
(painstakingly) on the local server.
> Hence, I'm not going to fight hard if you really want
> to do it. But I remain unconvinced that the cost/benefit tradeoff
> is attractive.
Thanks. Pending one last look, I'm planning to move ahead with it
unless there are any further objections or concerns.
David
{kind=link}
{kind=link}