Re: Optimising compactify_tuples() - Mailing list pgsql-hackers
| From | David Rowley |
|---|---|
| Subject | Re: Optimising compactify_tuples() |
| Date | |
| Msg-id | CAApHDvqYVORiZxq2xPvP6_ndmmsTkvr6jSYv4UTNaFa5i1kd=Q@mail.gmail.com Whole thread |
| In response to | Re: Optimising compactify_tuples() (Thomas Munro <thomas.munro@gmail.com>) |
| Responses |
Re: Optimising compactify_tuples()
Re: Optimising compactify_tuples() Re: Optimising compactify_tuples() |
| List | pgsql-hackers |
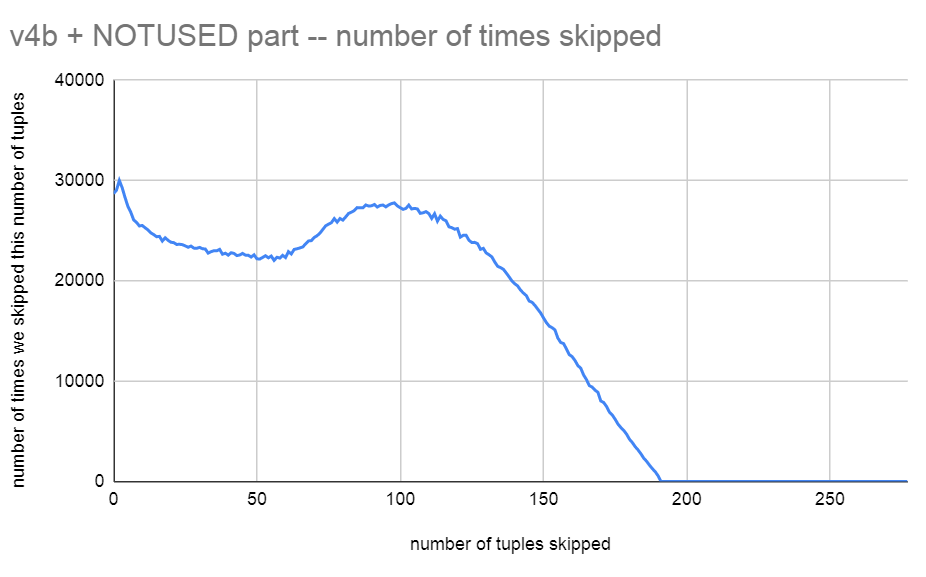
On Thu, 10 Sep 2020 at 10:40, Thomas Munro <thomas.munro@gmail.com> wrote: > > I wonder if we could also identify a range at the high end that is > already correctly sorted and maximally compacted so it doesn't even > need to be copied out. I've experimented quite a bit with this patch today. I think I've tested every idea you've mentioned here, so there's quite a lot of information to share. I did write code to skip the copy to the separate buffer for tuples that are already in the correct place and with a version of the patch which keeps tuples in their traditional insert order (later lineitem's tuple located earlier in the page) I see a generally a very large number of tuples being skipped with this method. See attached v4b_skipped_tuples.png. The vertical axis is the number of compactify_tuple() calls during the benchmark where we were able to skip that number of tuples. The average skipped tuples overall calls during recovery was 81 tuples, so we get to skip about half the tuples in the page doing this on this benchmark. > > With the attached v3, performance is better. The test now runs > > recovery 65.6 seconds, vs master's 148.5 seconds. So about 2.2x > > faster. > > On my machine I'm seeing 57s, down from 86s on unpatched master, for > the simple pgbench workload from > https://github.com/macdice/redo-bench/. That's not quite what you're > reporting but it still blows the doors off the faster sorting patch, > which does it in 74s. Thanks for running the numbers on that. I might be seeing a bit more gain as I dropped the fillfactor down to 85. That seems to cause more calls to compactify_tuples(). > So one question is whether we want to do the order-reversing as part > of this patch, or wait for a more joined-up project to make lots of > code paths collude on making scan order match memory order > (corellation = 1). Most or all of the gain from your patch would > presumably still apply if did the exact opposite and forced offset > order to match reverse-item ID order (correlation = -1), which also > happens to be the initial state when you insert tuples today; you'd > still tend towards a state that allows nice big memmov/memcpy calls > during page compaction. IIUC currently we start with correlation -1 > and then tend towards correlation = 0 after many random updates > because we can't change the order, so it gets scrambled over time. > I'm not sure what I think about that. So I did lots of benchmarking with both methods and my conclusion is that I think we should stick to the traditional INSERT order with this patch. But we should come back and revisit that more generally one day. The main reason that I'm put off flipping the tuple order is that it significantly reduces the number of times we hit the preordered case. We go to all the trouble of reversing the order only to have it broken again when we add 1 more tuple to the page. If we keep this the traditional way, then it's much more likely that we'll maintain that pre-order and hit the more optimal memmove code path. To put that into numbers, using my benchmark, I see 13.25% of calls to compactify_tuples() when the tuple order is reversed (i.e earlier lineitems earlier in the page). However, if I keep the lineitems in their proper order where earlier lineitems are at the end of the page then I hit the preordered case 60.37% of the time. Hitting the presorted case really that much more often is really speeding things up even further. I've attached some benchmark results as benchmark_table.txt, and benchmark_chart.png. The v4 patch implements your copy skipping idea for the prefix of tuples which are already in the correct location. v4b is that patch but changed to keep the tuples in the traditional order. v5 was me experimenting further by adding a precalculated end of tuple Offset to save having to calculate it each time by adding itemoff and alignedlen together. It's not an improvement, so but I just wanted to mention that I tried it. If you look the benchmark results, you'll see that v4b is the winner. The v4b + NOTUSED is me changing the #ifdef NOTUSED part so that we use the smarter code to populate the backup buffer. Remember that I got 60.37% of calls hitting the preordered case in v4b, so less than 40% had to do the backup buffer. So the slowness of that code is more prominent when you compare v5 to v5 NOTUSED since the benchmark is hitting the non-preordered code 86.75% of the time with that version. > PS You might as well post future patches with .patch endings so that > the cfbot tests them; it seems pretty clear now that a patch to > optimise sorting (as useful as it may be for future work) can't beat a > patch to skip it completely. I took the liberty of switching the > author and review names in the commitfest entry to reflect this. Thank you. I've attached v4b (b is for backwards since the traditional backwards tuple order is maintained). v4b seems to be able to run my benchmark in 63 seconds. I did 10 runs today of yesterday's v3 patch and got an average of 72.8 seconds, so quite a big improvement from yesterday. The profile indicates there's now bigger fish to fry: 25.25% postgres postgres [.] PageRepairFragmentation 13.57% postgres libc-2.31.so [.] __memmove_avx_unaligned_erms 10.87% postgres postgres [.] hash_search_with_hash_value 7.07% postgres postgres [.] XLogReadBufferExtended 5.57% postgres postgres [.] compactify_tuples 4.06% postgres postgres [.] PinBuffer 2.78% postgres postgres [.] heap_xlog_update 2.42% postgres postgres [.] hash_bytes 1.65% postgres postgres [.] XLogReadRecord 1.55% postgres postgres [.] LWLockRelease 1.42% postgres postgres [.] SlruSelectLRUPage 1.38% postgres postgres [.] PageGetHeapFreeSpace 1.20% postgres postgres [.] DecodeXLogRecord 1.16% postgres postgres [.] pg_comp_crc32c_sse42 1.15% postgres postgres [.] StartupXLOG 1.14% postgres postgres [.] LWLockAttemptLock 0.90% postgres postgres [.] ReadBuffer_common 0.81% postgres libc-2.31.so [.] __memcmp_avx2_movbe 0.71% postgres postgres [.] smgropen 0.65% postgres postgres [.] PageAddItemExtended 0.60% postgres postgres [.] PageIndexTupleOverwrite 0.57% postgres postgres [.] ReadPageInternal 0.54% postgres postgres [.] UnpinBuffer.constprop.0 0.53% postgres postgres [.] AdvanceNextFullTransactionIdPastXid I'll still class v4b as POC grade. I've not thought too hard about comments or done a huge amount of testing on it. We'd better decide on all the exact logic first. I've also attached another tiny patch that I think is pretty useful separate from this. It basically changes: LOG: redo done at 0/D518FFD0 into: LOG: redo done at 0/D518FFD0 system usage: CPU: user: 58.93 s, system: 0.74 s, elapsed: 62.31 s (I was getting sick of having to calculate the time spent from the log timestamps.) David
Attachment
{kind=link}
{kind=link}
pgsql-hackers by date: