Re: B-Tree support function number 3 (strxfrm() optimization) - Mailing list pgsql-hackers
| From | Peter Geoghegan |
|---|---|
| Subject | Re: B-Tree support function number 3 (strxfrm() optimization) |
| Date | |
| Msg-id | CAM3SWZTyjOzY7_i+xFf3KyP0mejw+fHH2ZT86Chh9PB48p_xJQ@mail.gmail.com Whole thread |
| In response to | Re: B-Tree support function number 3 (strxfrm() optimization) (Robert Haas <robertmhaas@gmail.com>) |
| Responses |
Re: B-Tree support function number 3 (strxfrm() optimization)
|
| List | pgsql-hackers |
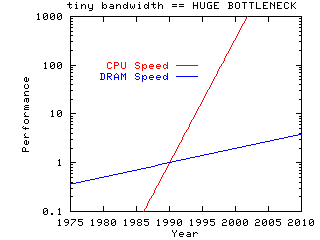
On Fri, Sep 12, 2014 at 11:38 AM, Robert Haas <robertmhaas@gmail.com> wrote: > Based on discussion thus far it seems that there's a possibility that > the trade-off may be different for short strings vs. long strings. If > the string is small enough to fit in the L1 CPU cache, then it may be > that memcmp() followed by strcoll() is not much more expensive than > strcoll(). That should be easy to figure out: write a standalone C > program that creates a bunch of arbitrary, fairly-short strings, say > 32 bytes, in a big array. Make the strings different near the end, > but not at the beginning. Then have the program either do strcoll() > on every pair (O(n^2)) or, with a #define, memcmp() followed by > strcoll() on every pair. It should be easy to see whether the > memcmp() adds 1% or 25% or 100%. I get where you're coming from now (I think). It seems like you're interested in getting a sense of what it would cost to do an opportunistic memcmp() in a universe where memory latency isn't by far the dominant cost (which it clearly is, as evidenced by my most recent benchmark where a variant of Heikki's highly unsympathetic SQL test case showed a ~1% regression). You've described a case with totally predictable access patterns, perfectly suited to prefetching, and with no other memory access bottlenecks. As I've said, this seems reasonable (at least with those caveats in mind). The answer to your high level question appears to be: the implementation (the totally opportunistic "memcmp() == 0" thing) benefits from the fact that we're always bottlenecked on memory, and to a fairly appreciable degree. I highly doubt that this is something that can fail to work out with real SQL queries, but anything that furthers our understanding of the optimization is a good thing. Of course, within tuplesort we're not really getting the totally opportunistic memcmp()s "for free" - rather, we're using a resource that we would not otherwise be able to use at all. This graph illustrates the historic trends of CPU and memory performance: http://www.cs.virginia.edu/stream/stream_logo.gif I find this imbalance quite remarkable - no wonder researchers are finding ways to make the best of the situation. To make matters worse, the per-core trends for memory bandwidth are now actually *negative growth*. We may actually be going backwards, if we assume that that's the bottleneck, and that we cannot parallelize things. Anyway, attached rough test program implements what you outline. This is for 30,000 32 byte strings (where just the final two bytes differ). On my laptop, output looks like this (edited to only show median duration in each case): """ Strings generated - beginning tests (baseline) duration of comparisons without useless memcmp()s: 13.445506 seconds duration of comparisons with useless memcmp()s: 17.720501 seconds """ It looks like about a 30% increase in run time when we always have useless memcmps(). You can change the constants around easily - let's consider 64 KiB strings now (by changing STRING_SIZE to 65536). In order to make the program not take too long, I also reduce the number of strings (N_STRINGS) from 30,000 to 1,000. If I do so, this is what I see as output: """ Strings generated - beginning tests (baseline) duration of comparisons without useless memcmp()s: 11.205683 seconds duration of comparisons with useless memcmp()s: 14.542997 seconds """ It looks like the overhead here is surprisingly consistent with the first run - again, about a 30% increase in run time. As for 1MiB strings (this time, with an N_STRINGS of 300): """ Strings generated - beginning tests (baseline) duration of comparisons without useless memcmp()s: 23.624183 seconds duration of comparisons with useless memcmp()s: 35.332728 seconds """ So, at this scale, the overhead gets quite a bit worse, but the case also becomes quite a bit less representative (if that's even possible). I suspect that the call stack's stupidly large size may be a problem here, but I didn't try and fix that. Does this answer your question? Are you intent on extrapolating across different platforms based on this test program, rather than looking at real SQL queries? While a certain amount of that makes sense, I think we should focus on queries that have some chance of being seen in real production PostgreSQL instances. Failing that, actual SQL queries. -- Peter Geoghegan
{kind=link}
Attachment
pgsql-hackers by date: