Re: Improving spin-lock implementation on ARM. - Mailing list pgsql-hackers
| From | Alexander Korotkov |
|---|---|
| Subject | Re: Improving spin-lock implementation on ARM. |
| Date | |
| Msg-id | CAPpHfdsGqVd6EJ4mr_RZVE5xSiCNBy4MuSvdTrKmTpM0eyWGpg@mail.gmail.com Whole thread |
| In response to | Re: Improving spin-lock implementation on ARM. (Alexander Korotkov <aekorotkov@gmail.com>) |
| Responses |
Re: Improving spin-lock implementation on ARM.
|
| List | pgsql-hackers |
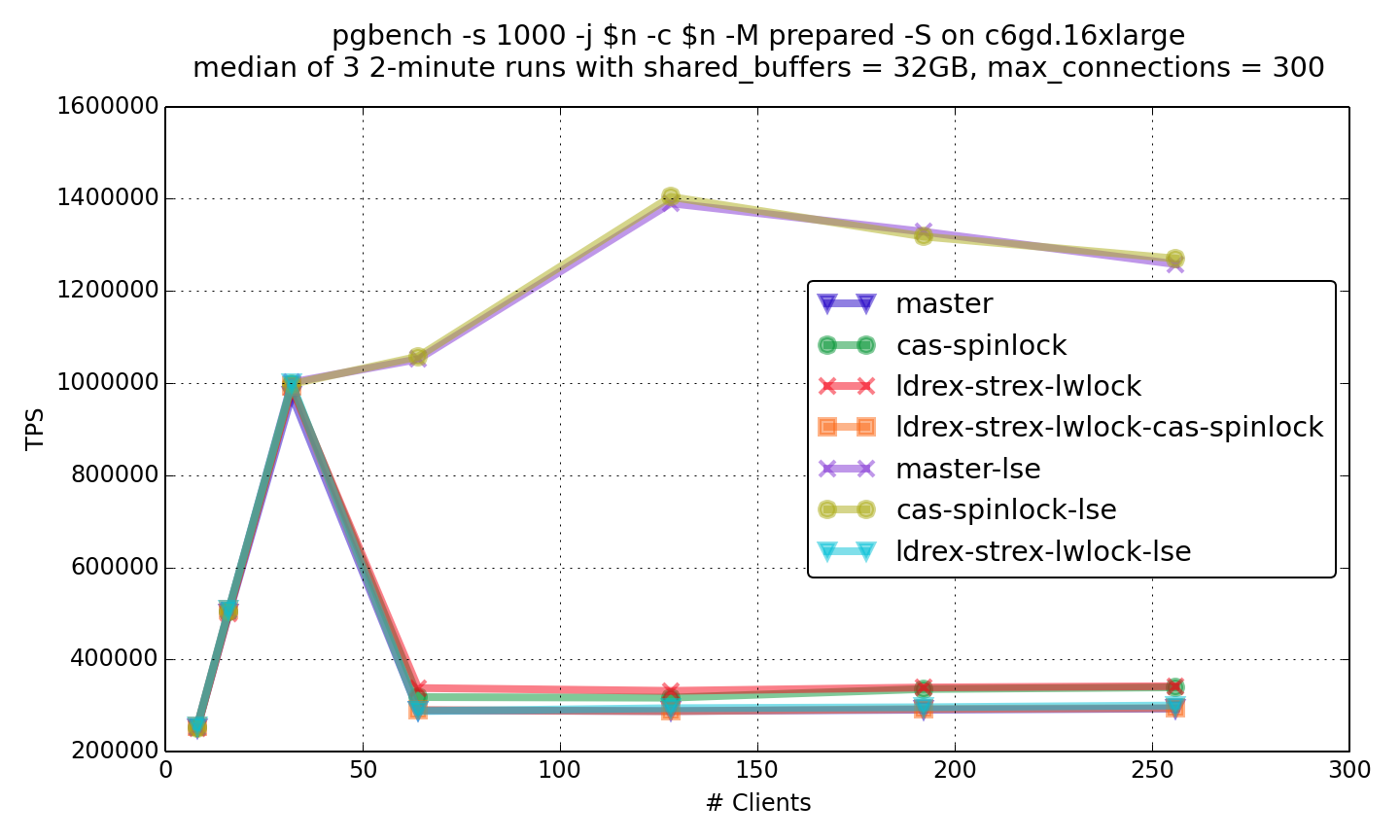
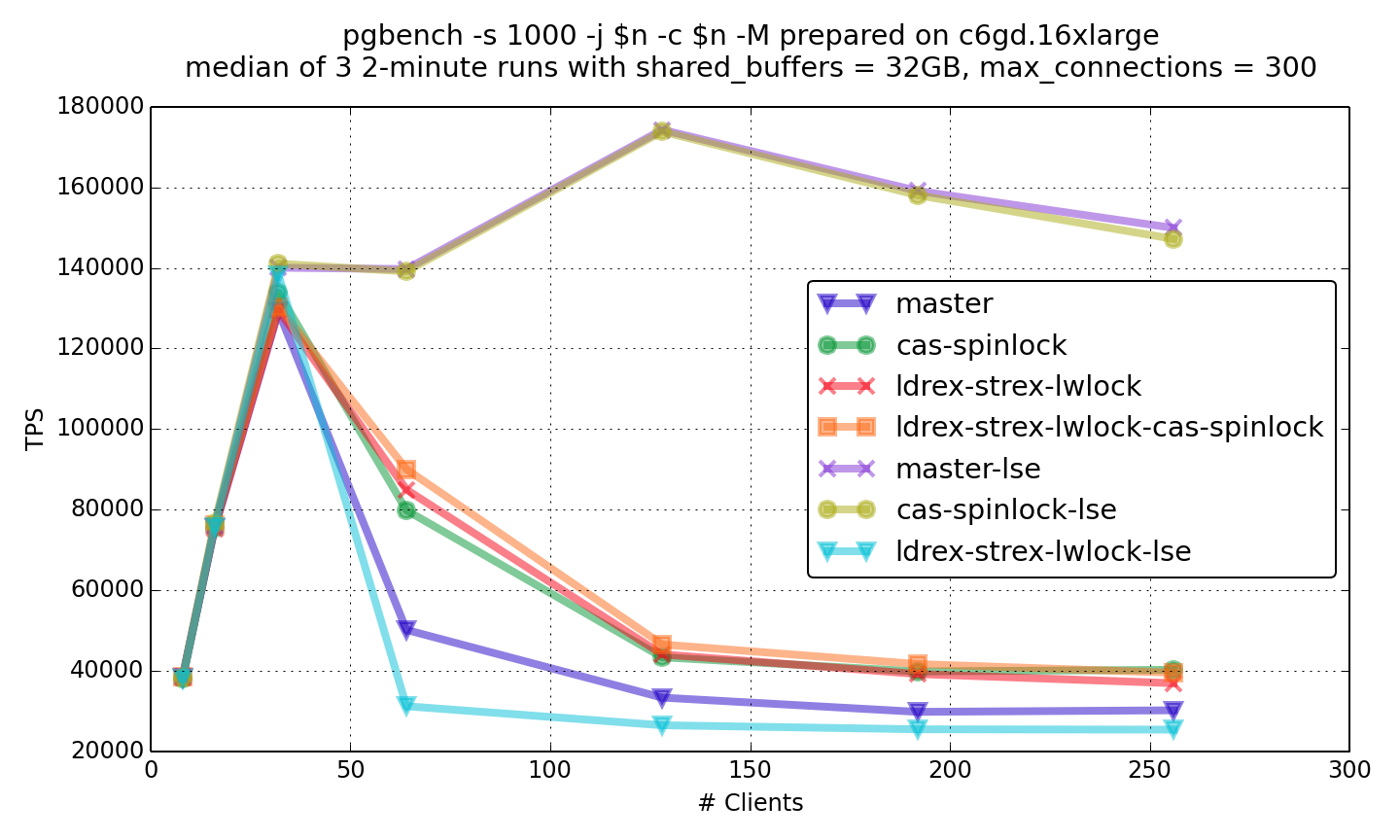
On Sat, Nov 28, 2020 at 1:31 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > I guess that might depend on the implementation of CAS and TAS. I bet > usage of CAS in spinlock gives advantage when ldxr/stxr are used, but > not when swpal/casa are used. I found out that I can force clang to > use swpal/casa by setting "-march=armv8-a+lse". I'm going to make > some experiments on a multicore AWS graviton2 instance with different > atomic implementation. I've made some benchmarks on c6gd.16xlarge ec2 instance with graviton2 processor of 64 virtual CPUs (graphs and raw results are attached). I've analyzed two patches: spinlock using cas by Krunal Bauskar, and my implementation of lwlock using lwrex/strex. My arm lwlock patch has the same idea as my previous patch for power: we can put lwlock attempt logic between lwrex and strex. In spite of my previous power patch, the arm patch doesn't contain assembly: instead I've used C-wrappers over lwrex/strex. The first series of experiments I've made using standard compiling options. So, LSE instructions from ARM v8.1 weren't used. Atomics were implemented using lwrex/strex pair. In the read-only benchmark, both spinlock (cas-spinlock graph) and lwlock (ldrew-strex-lwlock graph) patches give observable performance gain of similar value. However, performance of combination of these patches (ldrew-strex-lwlock-cas-spinlock graph) is close to performance of unpatched version. That could be counterintuitive, but I've rechecked that multiple times. In the read-write benchmark, both spinlock and lwlock patches give more significant performance gain, and lwlock patch gives more effect than spinlock patch. Noticeable, that combination of patches now gives some cumulative effect instead of counterintuitive slowdown. Then I've tried to compile postgres with LSE instruction using "-march=armv8-a+lse" flag with clang (graphs with -lse suffix). The effect of LSE is HUGE!!! Unpatched version with LSE is times faster than any version without LSE on high concurrency. In the both read-only and read-write benchmarks spinlock patch doesn't show any significant difference. The lwlock patch shows a great slowdown with LSE. Noticeable, in read-write benchmark, lwlock patch shows worse results than unpatched version without LSE. Probably, combining different atomics implementations isn't a good idea. It seems that ARM Kunpeng 920 should support ARM v8.1. I wonder if the published benchmarks results were made with LSE. I suspect that it was not. It would be nice to repeat the same benchmarks with LSE. I'd like to ask Krunal Bauskar and Amit Khandekar to repeat these benchmarks with LSE. My preliminary conclusions are so: 1) Since the effect of LSE is so huge, we should advise users of multicore ARM servers to compile PostgreSQL with LSE support. We probably should provide separate packaging for ARM v8.1 and higher (packages for ARM v8 are still needed for raspberry etc). 2) It seems that atomics in ARM v8.1 becomes very similar to x86 atomics, and it doesn't need special optimizations. And I think ARM v8 processors don't have so many cores and aren't so heavily used in high-concurrent environments. So, special optimizations for ARM v8 probably aren't worth it. Links 1. https://www.postgresql.org/message-id/CAB10pyamDkTFWU_BVGeEVmkc8%3DEhgCjr6QBk02SCdJtKpHkdFw%40mail.gmail.com 2. https://www.postgresql.org/message-id/CAPpHfdsKrh7c7P8-5eG-qW3VQobybbwqH%3DgL5Ck%2BdOES-gBbFg%40mail.gmail.com ------ Regards, Alexander Korotkov
Attachment
{kind=link}
{kind=link}
pgsql-hackers by date: