Re: WIP: "More fair" LWLocks - Mailing list pgsql-hackers
| From | Alexander Korotkov |
|---|---|
| Subject | Re: WIP: "More fair" LWLocks |
| Date | |
| Msg-id | CAPpHfdsZPS=b85cxcqO7YjoH3vtPBKYhVRLkZ_WMVbfZB-3bHA@mail.gmail.com Whole thread |
| In response to | Re: WIP: "More fair" LWLocks (Dmitry Dolgov <9erthalion6@gmail.com>) |
| Responses |
Re: WIP: "More fair" LWLocks
|
| List | pgsql-hackers |
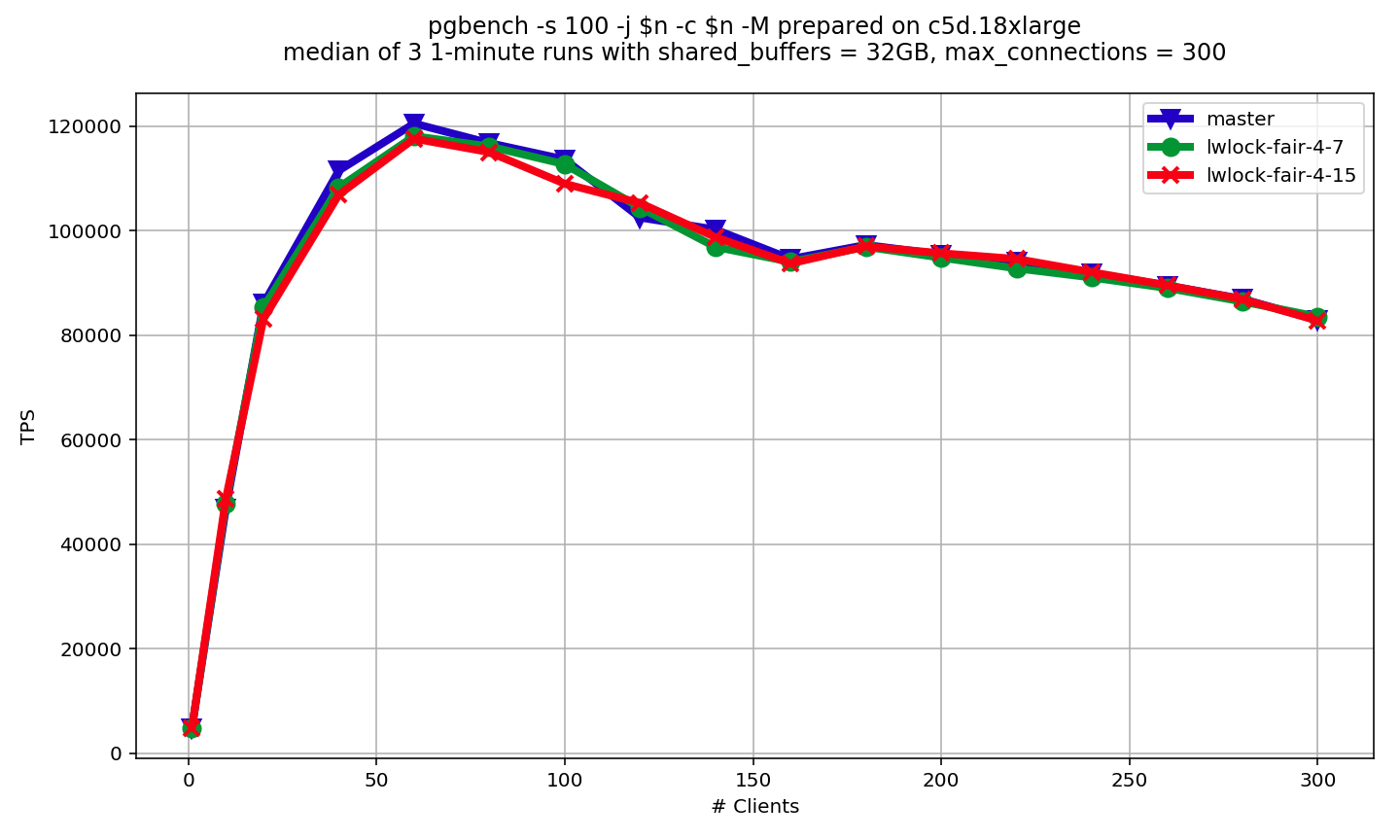
On Sun, Sep 9, 2018 at 7:20 PM Dmitry Dolgov <9erthalion6@gmail.com> wrote: > > I've tested the second patch a bit using my bpf scripts to measure the lock > contention. These scripts are still under the development, so there maybe some > rough edges and of course they make things slower, but so far the > event-by-event tracing correlates quite good with a perf script output. For > highly contented case (I simulated it using random_zipfian) I've even got some > visible improvement in the time distribution, but in an interesting way - there > is almost no difference in the distribution of time for waiting on > exclusive/shared locks, but a similar metric for holding shared locks is > somehow has bigger portion of short time frames: > > # without the patch > > Shared lock holding time > > hold time (us) : count distribution > 0 -> 1 : 17897059 |************************** | > 2 -> 3 : 27306589 |****************************************| > 4 -> 7 : 6386375 |********* | > 8 -> 15 : 5103653 |******* | > 16 -> 31 : 3846960 |***** | > 32 -> 63 : 118039 | | > 64 -> 127 : 15588 | | > 128 -> 255 : 2791 | | > 256 -> 511 : 1037 | | > 512 -> 1023 : 137 | | > 1024 -> 2047 : 3 | | > > # with the patch > > Shared lock holding time > hold time (us) : count distribution > 0 -> 1 : 20909871 |******************************** | > 2 -> 3 : 25453610 |****************************************| > 4 -> 7 : 6012183 |********* | > 8 -> 15 : 5364837 |******** | > 16 -> 31 : 3606992 |***** | > 32 -> 63 : 112562 | | > 64 -> 127 : 13483 | | > 128 -> 255 : 2593 | | > 256 -> 511 : 1029 | | > 512 -> 1023 : 138 | | > 1024 -> 2047 : 7 | | > > So looks like the locks, queued as implemented in this patch, are released > faster than without this queue (probably it reduces contention in the less > expected way). I've tested it also using c5d.18xlarge, although with a bit > different options (more pgbench scale, shared_buffers, number of clients is > fixed at 72) and I'll try to make few more rounds with different options. > > For the case of uniform distribution (just a normal read-write workload) in the > same environment I don't see yet any significant differences in time > distribution between the patched version and the master, which is a bit > surprising for me. Can you point out some analysis why this kind of "fairness" > introduces significant performance regression? Dmitry, thank you for your feedback and experiments! Our LWLock allow many shared lockers to take a lock at the same time, while exclusive locker can be only one. On high contended LWLock's flood of shared lockers can be intensive, but all of them are processed in parallel. If we interrupt shared lockers with exclusive lock, then all of them have to wait. If even we do this rarely, shared lockers are many. So, performance impact of this wait is multiplied by the number of shared lockers. Therefore, overall overhead appears to be significant. Thus, I would say that some overhead is inevitable consequence of this patch. My point is that it might be possible to keep overhead negligible in typical use-cases. I made few more versions of this patch. * lwlock-fair-3.patch In lwlock-fair-2.patch we wait for single shared locker to proceed before switching to "fair" mode. Idea of lwlock-fair-3.patch is to extend this period: we wait not for one, but for 7 _sequential_ shared lockers. Free bits of LWLock state are used to hold number of sequential shared lockers processed. Benchmark results are shown on lwlock-fair-3-rw.png. As we can see, there is some win in comparison with 2nd version for 60 and 80 clients. But for 100 clients and more there is almost no effect. So, I think it doesn't worth trying numbers greater than 7. It's better to look for other approaches. I've explained myself why effect lwlock-fair-3.patch was not enough as following. We have group xid clearing and group clog update, which accumulates queue. Once exclusive lock is obtained, all the queue is processed at once. Thus, larger queues are accumulated, higher performance we have. So, 7 (or whatever else fixed number) sequential shared lockers might be not enough to accumulate large enough queue for every number of clients. * lwlock-fair-4-7.patch and lwlock-fair-4-15.patch The idea of 4th version of this patch is to reset counter to zero, when new process is added to exclusive waiters queue. So, we wait exclusive waiters queue to stabilize before switching to "fair" mode. This includes LWLock queue itself and queues of group xid clearing and group clog update. I made experiments with waiting for 7 or 15 sequential shared lockers. In order to implement 15 of them I've to cut one bit from LW_SHARED_MASK (it's not something I propose, but just made for experiment). The results are given on lwlock-fair-4-rw.png. As we can see, overhead is much smaller (and almost no difference between 7 and 15). The thing, which is worrying me is that I've added extra atomic instructions, which can still cause an overhead. I'm going to continue my experiments. I would like to have something like 4th version of patch, but without extra atomic instructions. May be by placing number of sequential shared lockers past into separate (non-atomic) variable. The feedback is welcome. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
{kind=link}
{kind=link}
pgsql-hackers by date: