Thread: Critical failure of standby
Hello,
We recently experienced a critical failure when failing to a DR environment.
This is in the following environment:
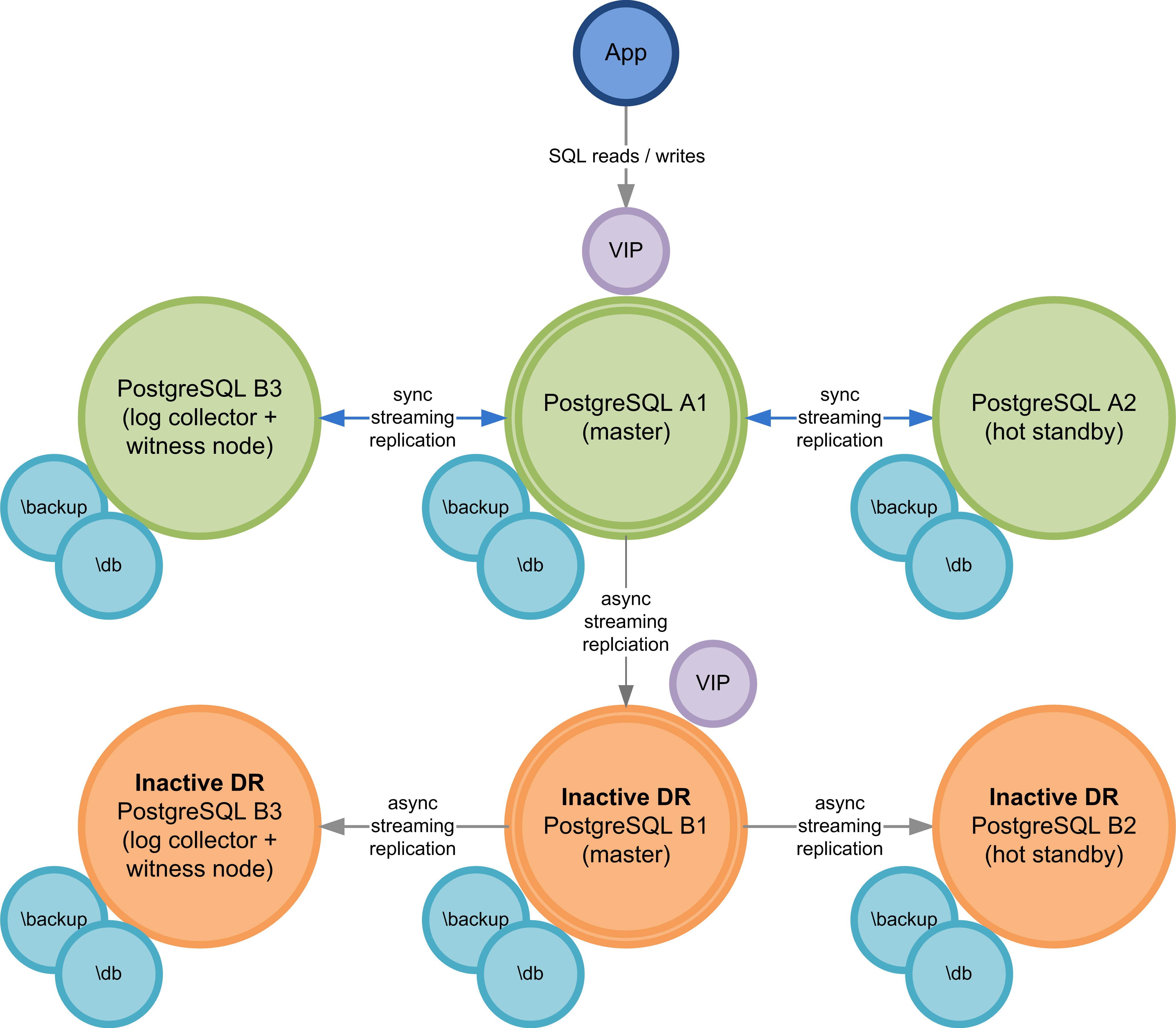
- 3 x PostgreSQL machines in Prod in a sync replication cluster
- 3 x PostgreSQL machines in DR, with a single machine async and the other two cascading from the first machine.
There was network failure which isolated Production from everything else, Production has no errors during this time (and has now come back OK).
DR did not tolerate the break, the following appeared in the logs and none of them can start postgres. There were no queries coming into DR at the time of the break.
Please note that the "Host Key verification failed" messages are due to the scp command not functioning. This means restore_command is not working to restore from the XLOG archive, but should not effect anything else.
2016-08-12 02:52:55 GMT [23205]: [9077-1] user=,db=,client= (0:00000)LOG: restartpoint starting: time
2016-08-12 02:57:25 GMT [23205]: [9078-1] user=,db=,client= (0:00000)LOG: restartpoint complete: wrote 13361 buffers (0.6%); 0 transaction log file(s) added, 0 removed, 3 recycled; write=269.972 s, sync=0.031 s, total=270.008 s; sync files=41, longest=0.004 s, average=0.000 s; distance=37747 kB, estimate=48968 kB
2016-08-12 02:57:25 GMT [23205]: [9079-1] user=,db=,client= (0:00000)LOG: recovery restart point at 3/7C7B0228
2016-08-12 02:57:25 GMT [23205]: [9080-1] user=,db=,client= (0:00000)DETAIL: last completed transaction was at log time 2016-08-12 02:57:24.033588+00
2016-08-12 02:57:55 GMT [23205]: [9081-1] user=,db=,client= (0:00000)LOG: restartpoint starting: time
2016-08-12 03:02:25 GMT [23205]: [9082-1] user=,db=,client= (0:00000)LOG: restartpoint complete: wrote 7196 buffers (0.3%); 0 transaction log file(s) added, 0 removed, 2 recycled; write=269.988 s, sync=0.014 s, total=270.007 s; sync files=42, longest=0.002 s, average=0.000 s; distance=79888 kB, estimate=79888 kB
2016-08-12 03:02:25 GMT [23205]: [9083-1] user=,db=,client= (0:00000)LOG: recovery restart point at 3/815B42C8
2016-08-12 03:02:25 GMT [23205]: [9084-1] user=,db=,client= (0:00000)DETAIL: last completed transaction was at log time 2016-08-12 03:02:15.07639+00
2016-08-12 03:02:55 GMT [23205]: [9085-1] user=,db=,client= (0:00000)LOG: restartpoint starting: time
2016-08-12 03:04:00 GMT [22350]: [2-1] user=,db=,client= (0:XX000)FATAL: terminating walreceiver due to timeout
Host key verification failed.^M
Host key verification failed.^M
2016-08-12 03:04:00 GMT [23188]: [9-1] user=,db=,client= (0:XX000)FATAL: invalid memory alloc request size 3445219328
2016-08-12 03:04:01 GMT [23182]: [5-1] user=,db=,client= (0:00000)LOG: startup process (PID 23188) exited with exit code 1
2016-08-12 03:04:01 GMT [23182]: [6-1] user=,db=,client= (0:00000)LOG: terminating any other active server processes
2016-08-12 03:04:01 GMT [22285]: [1-1] user=replication,db=[unknown],
2016-08-12 03:04:01 GMT [22285]: [2-1] user=replication,db=[unknown],
2016-08-12 03:04:01 GMT [22285]: [3-1] user=replication,db=[unknown],
2016-08-12 03:04:01 GMT [22286]: [1-1] user=replication,db=[unknown],
2016-08-12 03:04:01 GMT [22286]: [2-1] user=replication,db=[unknown],
2016-08-12 03:04:01 GMT [22286]: [3-1] user=replication,db=[unknown],
2016-08-12 03:04:01 GMT [23182]: [7-1] user=,db=,client= (0:00000)LOG: archiver process (PID 23207) exited with exit code 1
2016-08-12 04:43:51 GMT [23614]: [1-1] user=,db=,client= (0:00000)LOG: database system was interrupted while in recovery at log time 2016-08-12 02:53:19 GMT
2016-08-12 04:43:51 GMT [23614]: [2-1] user=,db=,client= (0:00000)HINT: If this has occurred more than once some data might be corrupted and you might need to choose an earlier recovery target.
2016-08-12 04:43:51 GMT [23615]: [1-1] user=postgres,db=postgres,
Host key verification failed.^M
2016-08-12 04:43:51 GMT [23614]: [3-1] user=,db=,client= (0:00000)LOG: entering standby mode
Host key verification failed.^M
Host key verification failed.^M
2016-08-12 04:43:51 GMT [23614]: [4-1] user=,db=,client= (0:00000)LOG: redo starts at 3/815B42C8
Host key verification failed.^M
Host key verification failed.^M
Host key verification failed.^M
2016-08-12 04:43:52 GMT [23643]: [1-1] user=postgres,db=postgres,
Host key verification failed.^M
Host key verification failed.^M
Host key verification failed.^M
Host key verification failed.^M
2016-08-12 04:43:53 GMT [23614]: [5-1] user=,db=,client= (0:00000)LOG: consistent recovery state reached at 3/8811DFF0
2016-08-12 04:43:53 GMT [23614]: [6-1] user=,db=,client= (0:XX000)FATAL: invalid memory alloc request size 3445219328
2016-08-12 04:43:53 GMT [23612]: [3-1] user=,db=,client= (0:00000)LOG: database system is ready to accept read only connections
2016-08-12 04:43:53 GMT [23612]: [4-1] user=,db=,client= (0:00000)LOG: startup process (PID 23614) exited with exit code 1
2016-08-12 04:43:53 GMT [23612]: [5-1] user=,db=,client= (0:00000)LOG: terminating any other active server processes
2016-08-12 04:43:53 GMT [23612]: [6-1] user=,db=,client= (0:00000)LOG: archiver process (PID 23627) exited with exit code 1
2016-08-12 04:44:04 GMT [23710]: [1-1] user=,db=,client= (0:00000)LOG: database system was interrupted while in recovery at log time 2016-08-12 02:53:19 GMT
2016-08-12 04:44:04 GMT [23710]: [2-1] user=,db=,client= (0:00000)HINT: If this has occurred more than once some data might be corrupted and you might need to choose an earlier recovery target.
Does anyone have any ideas? It looks to me like some sort of bug / error with the replication protocol or maybe some corruption on the master which wasn't noticed and fed across?
If that's the case would checksums help here? Are the computed on the standby?
Cheers,
James Sewell,
Solutions Architect

Suite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009
The contents of this email are confidential and may be subject to legal or professional privilege and copyright. No representation is made that this email is free of viruses or other defects. If you have received this communication in error, you may not copy or distribute any part of it or otherwise disclose its contents to anyone. Please advise the sender of your incorrect receipt of this correspondence.
On Fri, Aug 12, 2016 at 1:39 AM, James Sewell <james.sewell@jirotech.com> wrote:
Hello,We recently experienced a critical failure when failing to a DR environment.This is in the following environment:
- 3 x PostgreSQL machines in Prod in a sync replication cluster
- 3 x PostgreSQL machines in DR, with a single machine async and the other two cascading from the first machine.
There was network failure which isolated Production from everything else, Production has no errors during this time (and has now come back OK).DR did not tolerate the break, the following appeared in the logs and none of them can start postgres. There were no queries coming into DR at the time of the break.Please note that the "Host Key verification failed" messages are due to the scp command not functioning. This means restore_command is not working to restore from the XLOG archive, but should not effect anything else.2016-08-12 02:52:55 GMT [23205]: [9077-1] user=,db=,client= (0:00000)LOG: restartpoint starting: time2016-08-12 02:57:25 GMT [23205]: [9078-1] user=,db=,client= (0:00000)LOG: restartpoint complete: wrote 13361 buffers (0.6%); 0 transaction log file(s) added, 0 removed, 3 recycled; write=269.972 s, sync=0.031 s, total=270.008 s; sync files=41, longest=0.004 s, average=0.000 s; distance=37747 kB, estimate=48968 kB2016-08-12 02:57:25 GMT [23205]: [9079-1] user=,db=,client= (0:00000)LOG: recovery restart point at 3/7C7B02282016-08-12 02:57:25 GMT [23205]: [9080-1] user=,db=,client= (0:00000)DETAIL: last completed transaction was at log time 2016-08-12 02:57:24.033588+002016-08-12 02:57:55 GMT [23205]: [9081-1] user=,db=,client= (0:00000)LOG: restartpoint starting: time2016-08-12 03:02:25 GMT [23205]: [9082-1] user=,db=,client= (0:00000)LOG: restartpoint complete: wrote 7196 buffers (0.3%); 0 transaction log file(s) added, 0 removed, 2 recycled; write=269.988 s, sync=0.014 s, total=270.007 s; sync files=42, longest=0.002 s, average=0.000 s; distance=79888 kB, estimate=79888 kB2016-08-12 03:02:25 GMT [23205]: [9083-1] user=,db=,client= (0:00000)LOG: recovery restart point at 3/815B42C82016-08-12 03:02:25 GMT [23205]: [9084-1] user=,db=,client= (0:00000)DETAIL: last completed transaction was at log time 2016-08-12 03:02:15.07639+002016-08-12 03:02:55 GMT [23205]: [9085-1] user=,db=,client= (0:00000)LOG: restartpoint starting: time2016-08-12 03:04:00 GMT [22350]: [2-1] user=,db=,client= (0:XX000)FATAL: terminating walreceiver due to timeoutHost key verification failed.^MHost key verification failed.^M2016-08-12 03:04:00 GMT [23188]: [9-1] user=,db=,client= (0:XX000)FATAL: invalid memory alloc request size 34452193282016-08-12 03:04:01 GMT [23182]: [5-1] user=,db=,client= (0:00000)LOG: startup process (PID 23188) exited with exit code 12016-08-12 03:04:01 GMT [23182]: [6-1] user=,db=,client= (0:00000)LOG: terminating any other active server processes2016-08-12 03:04:01 GMT [22285]: [1-1] user=replication,db=[unknown],client=10.8.0.14 10.8.0.14(55826) (0:57P02)WARNING: terminating connection because of crash of another server process 2016-08-12 03:04:01 GMT [22285]: [2-1] user=replication,db=[unknown],client=10.8.0.14 10.8.0.14(55826) (0:57P02)DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory. 2016-08-12 03:04:01 GMT [22285]: [3-1] user=replication,db=[unknown],client=10.8.0.14 10.8.0.14(55826) (0:57P02)HINT: In a moment you should be able to reconnect to the database and repeat your command. 2016-08-12 03:04:01 GMT [22286]: [1-1] user=replication,db=[unknown],client=10.8.0.32 10.8.0.32(56442) (0:57P02)WARNING: terminating connection because of crash of another server process 2016-08-12 03:04:01 GMT [22286]: [2-1] user=replication,db=[unknown],client=10.8.0.32 10.8.0.32(56442) (0:57P02)DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory. 2016-08-12 03:04:01 GMT [22286]: [3-1] user=replication,db=[unknown],client=10.8.0.32 10.8.0.32(56442) (0:57P02)HINT: In a moment you should be able to reconnect to the database and repeat your command. 2016-08-12 03:04:01 GMT [23182]: [7-1] user=,db=,client= (0:00000)LOG: archiver process (PID 23207) exited with exit code 12016-08-12 04:43:51 GMT [23614]: [1-1] user=,db=,client= (0:00000)LOG: database system was interrupted while in recovery at log time 2016-08-12 02:53:19 GMT2016-08-12 04:43:51 GMT [23614]: [2-1] user=,db=,client= (0:00000)HINT: If this has occurred more than once some data might be corrupted and you might need to choose an earlier recovery target.2016-08-12 04:43:51 GMT [23615]: [1-1] user=postgres,db=postgres,client=[local] [local] (0:57P03)FATAL: the database system is starting up Host key verification failed.^M2016-08-12 04:43:51 GMT [23614]: [3-1] user=,db=,client= (0:00000)LOG: entering standby modeHost key verification failed.^MHost key verification failed.^M2016-08-12 04:43:51 GMT [23614]: [4-1] user=,db=,client= (0:00000)LOG: redo starts at 3/815B42C8Host key verification failed.^MHost key verification failed.^MHost key verification failed.^M2016-08-12 04:43:52 GMT [23643]: [1-1] user=postgres,db=postgres,client=[local] [local] (0:57P03)FATAL: the database system is starting up Host key verification failed.^MHost key verification failed.^MHost key verification failed.^MHost key verification failed.^M2016-08-12 04:43:53 GMT [23614]: [5-1] user=,db=,client= (0:00000)LOG: consistent recovery state reached at 3/8811DFF02016-08-12 04:43:53 GMT [23614]: [6-1] user=,db=,client= (0:XX000)FATAL: invalid memory alloc request size 34452193282016-08-12 04:43:53 GMT [23612]: [3-1] user=,db=,client= (0:00000)LOG: database system is ready to accept read only connections2016-08-12 04:43:53 GMT [23612]: [4-1] user=,db=,client= (0:00000)LOG: startup process (PID 23614) exited with exit code 12016-08-12 04:43:53 GMT [23612]: [5-1] user=,db=,client= (0:00000)LOG: terminating any other active server processes2016-08-12 04:43:53 GMT [23612]: [6-1] user=,db=,client= (0:00000)LOG: archiver process (PID 23627) exited with exit code 12016-08-12 04:44:04 GMT [23710]: [1-1] user=,db=,client= (0:00000)LOG: database system was interrupted while in recovery at log time 2016-08-12 02:53:19 GMT2016-08-12 04:44:04 GMT [23710]: [2-1] user=,db=,client= (0:00000)HINT: If this has occurred more than once some data might be corrupted and you might need to choose an earlier recovery target.Does anyone have any ideas? It looks to me like some sort of bug / error with the replication protocol or maybe some corruption on the master which wasn't noticed and fed across?If that's the case would checksums help here? Are the computed on the standby?Cheers,James Sewell,Solutions ArchitectSuite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009
The contents of this email are confidential and may be subject to legal or professional privilege and copyright. No representation is made that this email is free of viruses or other defects. If you have received this communication in error, you may not copy or distribute any part of it or otherwise disclose its contents to anyone. Please advise the sender of your incorrect receipt of this correspondence.
>2016-08-12 03:04:00 GMT [23188]: [9-1] user=,db=,client= (0:XX000)FATAL: invalid memory alloc request size 3445219328
I'm not sure, but I'd double check your shared_memory spec both in postgresql.conf and /proc/sys/kernel/shmmax
(or /etc/sysctl.conf) in DR
--
Melvin Davidson
I reserve the right to fantasize. Whether or not you
wish to share my fantasy is entirely up to you.
I reserve the right to fantasize. Whether or not you
wish to share my fantasy is entirely up to you.
James Sewell wrote: > 2016-08-12 04:43:53 GMT [23614]: [5-1] user=,db=,client= (0:00000)LOG: consistent recovery state reached at 3/8811DFF0 > 2016-08-12 04:43:53 GMT [23614]: [6-1] user=,db=,client= (0:XX000)FATAL: invalid memory alloc request size 3445219328 > 2016-08-12 04:43:53 GMT [23612]: [3-1] user=,db=,client= (0:00000)LOG: database system is ready to accept read only connections > 2016-08-12 04:43:53 GMT [23612]: [4-1] user=,db=,client= (0:00000)LOG: startup process (PID 23614) exited with exit code1 > 2016-08-12 04:43:53 GMT [23612]: [5-1] user=,db=,client= (0:00000)LOG: terminating any other active server processes > 2016-08-12 04:43:53 GMT [23612]: [6-1] user=,db=,client= (0:00000)LOG: archiver process (PID 23627) exited with exitcode 1 What version is this? Hm, so the startup process finds the consistent point (which signals postmaster so that line 23612/3 says "ready to accept read-only conns") and immediately dies because of the invalid memory alloc error. I suppose that error must be while trying to process some xlog record, but without a xlog address it's difficult to say anything. I suppose you could try to pg_xlogdump WAL starting at the last known good address 3/8811DFF0 but I wouldn't know what to look for. One strange thing is that xlog replay sets up an error context, so you would have had a line like "xlog redo HEAP" etc, but there's nothing here. So maybe the allocation is not exactly in xlog replay, but something different. We'd need to see a backtrace in order to see what. Since this occurs in the startup process, probably the easiest way is to patch the source to turn that error into PANIC, then re-run and examine the resulting core file. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
(from other thread)
- 9.5.3
- Redhat 7.2 on VMWare
- Single PostgreSQL instance one each machine
- Every machine in DR became corrupt, so interestingly this must have been sent to the two cascading nodes via WAL before the crash on the hub DR node
- No OS logs indicating anything abnormal
I think the key looks like the (legitimate) loss of network to the Prod master, then:
(0:XX000)FATAL: invalid memory alloc request size 3445219328
Everything seems to go wrong from there. Are WAL segments checked for integrity once they are received?
James Sewell,
PostgreSQL Team Lead / Solutions Architect
Suite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009
On Sat, Aug 13, 2016 at 7:43 AM, James Sewell <james.sewell@jirotech.com> wrote:
It's on 9.5.3.I've actually created this mail twice (I sent once as an unregistered address and assumed it would be dropped). I sent a diagram to the other one, I'll forward that mail here now for completeness.Cheers,James Sewell,PostgreSQL Team Lead / Solutions ArchitectSuite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009On Sat, Aug 13, 2016 at 5:20 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:James Sewell wrote:
> 2016-08-12 04:43:53 GMT [23614]: [5-1] user=,db=,client= (0:00000)LOG: consistent recovery state reached at 3/8811DFF0
> 2016-08-12 04:43:53 GMT [23614]: [6-1] user=,db=,client= (0:XX000)FATAL: invalid memory alloc request size 3445219328
> 2016-08-12 04:43:53 GMT [23612]: [3-1] user=,db=,client= (0:00000)LOG: database system is ready to accept read only connections
> 2016-08-12 04:43:53 GMT [23612]: [4-1] user=,db=,client= (0:00000)LOG: startup process (PID 23614) exited with exit code 1
> 2016-08-12 04:43:53 GMT [23612]: [5-1] user=,db=,client= (0:00000)LOG: terminating any other active server processes
> 2016-08-12 04:43:53 GMT [23612]: [6-1] user=,db=,client= (0:00000)LOG: archiver process (PID 23627) exited with exit code 1
What version is this?
Hm, so the startup process finds the consistent point (which signals
postmaster so that line 23612/3 says "ready to accept read-only conns")
and immediately dies because of the invalid memory alloc error. I
suppose that error must be while trying to process some xlog record, but
without a xlog address it's difficult to say anything. I suppose you
could try to pg_xlogdump WAL starting at the last known good address
3/8811DFF0 but I wouldn't know what to look for.
One strange thing is that xlog replay sets up an error context, so you
would have had a line like "xlog redo HEAP" etc, but there's nothing
here. So maybe the allocation is not exactly in xlog replay, but
something different. We'd need to see a backtrace in order to see what.
Since this occurs in the startup process, probably the easiest way is to
patch the source to turn that error into PANIC, then re-run and examine
the resulting core file.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
James Sewell,
PostgreSQL Team Lead / Solutions Architect
Suite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009
On Sat, Aug 13, 2016 at 5:20 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
James Sewell wrote:
> 2016-08-12 04:43:53 GMT [23614]: [5-1] user=,db=,client= (0:00000)LOG: consistent recovery state reached at 3/8811DFF0
> 2016-08-12 04:43:53 GMT [23614]: [6-1] user=,db=,client= (0:XX000)FATAL: invalid memory alloc request size 3445219328
> 2016-08-12 04:43:53 GMT [23612]: [3-1] user=,db=,client= (0:00000)LOG: database system is ready to accept read only connections
> 2016-08-12 04:43:53 GMT [23612]: [4-1] user=,db=,client= (0:00000)LOG: startup process (PID 23614) exited with exit code 1
> 2016-08-12 04:43:53 GMT [23612]: [5-1] user=,db=,client= (0:00000)LOG: terminating any other active server processes
> 2016-08-12 04:43:53 GMT [23612]: [6-1] user=,db=,client= (0:00000)LOG: archiver process (PID 23627) exited with exit code 1
What version is this?
Hm, so the startup process finds the consistent point (which signals
postmaster so that line 23612/3 says "ready to accept read-only conns")
and immediately dies because of the invalid memory alloc error. I
suppose that error must be while trying to process some xlog record, but
without a xlog address it's difficult to say anything. I suppose you
could try to pg_xlogdump WAL starting at the last known good address
3/8811DFF0 but I wouldn't know what to look for.
One strange thing is that xlog replay sets up an error context, so you
would have had a line like "xlog redo HEAP" etc, but there's nothing
here. So maybe the allocation is not exactly in xlog replay, but
something different. We'd need to see a backtrace in order to see what.
Since this occurs in the startup process, probably the easiest way is to
patch the source to turn that error into PANIC, then re-run and examine
the resulting core file.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
The contents of this email are confidential and may be subject to legal or professional privilege and copyright. No representation is made that this email is free of viruses or other defects. If you have received this communication in error, you may not copy or distribute any part of it or otherwise disclose its contents to anyone. Please advise the sender of your incorrect receipt of this correspondence.
Hello,
I double posted this (posted once from an unregistered email and assumed it would be junked).
I'm continuing all discussion on the other thread now.
Cheers,
James Sewell,
PostgreSQL Team Lead / Solutions Architect
Suite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009
On Sat, Aug 13, 2016 at 5:20 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
James Sewell wrote:
> 2016-08-12 04:43:53 GMT [23614]: [5-1] user=,db=,client= (0:00000)LOG: consistent recovery state reached at 3/8811DFF0
> 2016-08-12 04:43:53 GMT [23614]: [6-1] user=,db=,client= (0:XX000)FATAL: invalid memory alloc request size 3445219328
> 2016-08-12 04:43:53 GMT [23612]: [3-1] user=,db=,client= (0:00000)LOG: database system is ready to accept read only connections
> 2016-08-12 04:43:53 GMT [23612]: [4-1] user=,db=,client= (0:00000)LOG: startup process (PID 23614) exited with exit code 1
> 2016-08-12 04:43:53 GMT [23612]: [5-1] user=,db=,client= (0:00000)LOG: terminating any other active server processes
> 2016-08-12 04:43:53 GMT [23612]: [6-1] user=,db=,client= (0:00000)LOG: archiver process (PID 23627) exited with exit code 1
What version is this?
Hm, so the startup process finds the consistent point (which signals
postmaster so that line 23612/3 says "ready to accept read-only conns")
and immediately dies because of the invalid memory alloc error. I
suppose that error must be while trying to process some xlog record, but
without a xlog address it's difficult to say anything. I suppose you
could try to pg_xlogdump WAL starting at the last known good address
3/8811DFF0 but I wouldn't know what to look for.
One strange thing is that xlog replay sets up an error context, so you
would have had a line like "xlog redo HEAP" etc, but there's nothing
here. So maybe the allocation is not exactly in xlog replay, but
something different. We'd need to see a backtrace in order to see what.
Since this occurs in the startup process, probably the easiest way is to
patch the source to turn that error into PANIC, then re-run and examine
the resulting core file.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
The contents of this email are confidential and may be subject to legal or professional privilege and copyright. No representation is made that this email is free of viruses or other defects. If you have received this communication in error, you may not copy or distribute any part of it or otherwise disclose its contents to anyone. Please advise the sender of your incorrect receipt of this correspondence.
Hello All,
The thing which I find a little worrying is that this 'corruption' was introduced either on the network from PROD -> DR, but then also cascaded to both other DR servers (either via replication or via archive_command).
Is WAL corruption checked for in any way on standby servers?.
Here is a link to a diagram of the current environment: http://imgur.com/a/MoKMo
I'll look into patching for a core-dump.
Cheers,
James Sewell,
Solutions Architect
Suite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009
On Sat, Aug 13, 2016 at 5:20 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:
James Sewell wrote:
> 2016-08-12 04:43:53 GMT [23614]: [5-1] user=,db=,client= (0:00000)LOG: consistent recovery state reached at 3/8811DFF0
> 2016-08-12 04:43:53 GMT [23614]: [6-1] user=,db=,client= (0:XX000)FATAL: invalid memory alloc request size 3445219328
> 2016-08-12 04:43:53 GMT [23612]: [3-1] user=,db=,client= (0:00000)LOG: database system is ready to accept read only connections
> 2016-08-12 04:43:53 GMT [23612]: [4-1] user=,db=,client= (0:00000)LOG: startup process (PID 23614) exited with exit code 1
> 2016-08-12 04:43:53 GMT [23612]: [5-1] user=,db=,client= (0:00000)LOG: terminating any other active server processes
> 2016-08-12 04:43:53 GMT [23612]: [6-1] user=,db=,client= (0:00000)LOG: archiver process (PID 23627) exited with exit code 1
What version is this?
Hm, so the startup process finds the consistent point (which signals
postmaster so that line 23612/3 says "ready to accept read-only conns")
and immediately dies because of the invalid memory alloc error. I
suppose that error must be while trying to process some xlog record, but
without a xlog address it's difficult to say anything. I suppose you
could try to pg_xlogdump WAL starting at the last known good address
3/8811DFF0 but I wouldn't know what to look for.
One strange thing is that xlog replay sets up an error context, so you
would have had a line like "xlog redo HEAP" etc, but there's nothing
here. So maybe the allocation is not exactly in xlog replay, but
something different. We'd need to see a backtrace in order to see what.
Since this occurs in the startup process, probably the easiest way is to
patch the source to turn that error into PANIC, then re-run and examine
the resulting core file.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
The contents of this email are confidential and may be subject to legal or professional privilege and copyright. No representation is made that this email is free of viruses or other defects. If you have received this communication in error, you may not copy or distribute any part of it or otherwise disclose its contents to anyone. Please advise the sender of your incorrect receipt of this correspondence.
On Thu, Aug 11, 2016 at 10:39 PM, James Sewell <james.sewell@jirotech.com> wrote:
Hello,We recently experienced a critical failure when failing to a DR environment.This is in the following environment:
- 3 x PostgreSQL machines in Prod in a sync replication cluster
- 3 x PostgreSQL machines in DR, with a single machine async and the other two cascading from the first machine.
There was network failure which isolated Production from everything else, Production has no errors during this time (and has now come back OK).DR did not tolerate the break, the following appeared in the logs and none of them can start postgres. There were no queries coming into DR at the time of the break.Please note that the "Host Key verification failed" messages are due to the scp command not functioning. This means restore_command is not working to restore from the XLOG archive, but should not effect anything else.
In my experience, PostgreSQL issues its own error messages when restore_command fails. So I see both the error from the command itself, and an error from PostgreSQL. Why don't you see that? Is the restore_command failing, but then reporting that it succeeded?
And if you can't get files from the XLOG archive, why do you think that that is OK?
Cheers,
Jeff
Those are all good questions.
Essentially this is a situation where DR is network separated from Prod - so I would expect the archive command to fail. I'll have to check the script it must not be passing the error back through to PostgreSQL.
This still shouldn't cause database corruption though right? - it's just not getting WALs.
Cheers,
James Sewell,
PostgreSQL Team Lead / Solutions Architect
Suite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009
On Tue, Aug 16, 2016 at 2:09 AM, Jeff Janes <jeff.janes@gmail.com> wrote:
On Thu, Aug 11, 2016 at 10:39 PM, James Sewell <james.sewell@jirotech.com> wrote:Hello,We recently experienced a critical failure when failing to a DR environment.This is in the following environment:
- 3 x PostgreSQL machines in Prod in a sync replication cluster
- 3 x PostgreSQL machines in DR, with a single machine async and the other two cascading from the first machine.
There was network failure which isolated Production from everything else, Production has no errors during this time (and has now come back OK).DR did not tolerate the break, the following appeared in the logs and none of them can start postgres. There were no queries coming into DR at the time of the break.Please note that the "Host Key verification failed" messages are due to the scp command not functioning. This means restore_command is not working to restore from the XLOG archive, but should not effect anything else.In my experience, PostgreSQL issues its own error messages when restore_command fails. So I see both the error from the command itself, and an error from PostgreSQL. Why don't you see that? Is the restore_command failing, but then reporting that it succeeded?And if you can't get files from the XLOG archive, why do you think that that is OK?Cheers,Jeff
The contents of this email are confidential and may be subject to legal or professional privilege and copyright. No representation is made that this email is free of viruses or other defects. If you have received this communication in error, you may not copy or distribute any part of it or otherwise disclose its contents to anyone. Please advise the sender of your incorrect receipt of this correspondence.
On 8/15/2016 7:23 PM, James Sewell wrote: > Those are all good questions. > > Essentially this is a situation where DR is network separated from > Prod - so I would expect the archive command to fail. I'll have to > check the script it must not be passing the error back through to > PostgreSQL. > > This still shouldn't cause database corruption though right? - it's > just not getting WALs. if the slave database is asking for the WAL's, it needs them. if it needs them and can't get them, then it can't catch up and start. -- john r pierce, recycling bits in santa cruz
Hey,
I understand that.
But a hot standby should always be ready to promote (given it originally caught up) right?
I think it's a moot point really as some sort of corruption has been introduced, the machines still won't wouldn't start after they could see the archive destination again.
Cheers,
James Sewell,
Solutions Architect
Suite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009
On Tue, Aug 16, 2016 at 12:36 PM, John R Pierce <pierce@hogranch.com> wrote:
On 8/15/2016 7:23 PM, James Sewell wrote:Those are all good questions.
Essentially this is a situation where DR is network separated from Prod - so I would expect the archive command to fail. I'll have to check the script it must not be passing the error back through to PostgreSQL.
This still shouldn't cause database corruption though right? - it's just not getting WALs.
if the slave database is asking for the WAL's, it needs them. if it needs them and can't get them, then it can't catch up and start.
--
john r pierce, recycling bits in santa cruz
--
Sent via pgsql-general mailing list (pgsql-general@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-general
The contents of this email are confidential and may be subject to legal or professional privilege and copyright. No representation is made that this email is free of viruses or other defects. If you have received this communication in error, you may not copy or distribute any part of it or otherwise disclose its contents to anyone. Please advise the sender of your incorrect receipt of this correspondence.
On Tue, Aug 16, 2016 at 1:10 PM James Sewell <james.sewell@jirotech.com> wrote:
Hey,
I understand that.But a hot standby should always be ready to promote (given it originally caught up) right?I think it's a moot point really as some sort of corruption has been introduced, the machines still won't wouldn't start after they could see the archive destination again.
Did you had a pending basebackup on the standby or a start backup (with no matching stop backup)?
Was there a crash/immediate shutdown on the standby during this network outage? Do you have full page writes/fsync disabled?
Cheers,James Sewell,Solutions ArchitectSuite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009On Tue, Aug 16, 2016 at 12:36 PM, John R Pierce <pierce@hogranch.com> wrote:On 8/15/2016 7:23 PM, James Sewell wrote:Those are all good questions.
Essentially this is a situation where DR is network separated from Prod - so I would expect the archive command to fail. I'll have to check the script it must not be passing the error back through to PostgreSQL.
This still shouldn't cause database corruption though right? - it's just not getting WALs.
if the slave database is asking for the WAL's, it needs them. if it needs them and can't get them, then it can't catch up and start.
--
john r pierce, recycling bits in santa cruz
--
Sent via pgsql-general mailing list (pgsql-general@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-general
The contents of this email are confidential and may be subject to legal or professional privilege and copyright. No representation is made that this email is free of viruses or other defects. If you have received this communication in error, you may not copy or distribute any part of it or otherwise disclose its contents to anyone. Please advise the sender of your incorrect receipt of this correspondence.
--
--
Best Regards
Sameer Kumar | DB Solution Architect
ASHNIK PTE. LTD.
101 Cecil Street, #11-11 Tong Eng Building, Singapore 069 533
T: +65 6438 3504 | M: +65 8110 0350
Skype: sameer.ashnik | www.ashnik.com
Hey Sameer,
As per the logs there was a crash of one standby, which seems to have corrupted that standby and the two cascading standby.
- No backups
- Full page writes enabled
- Fsync enabled
Cheers,
James Sewell,
Solutions Architect
Suite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009
On Tue, Aug 16, 2016 at 3:15 PM, Sameer Kumar <sameer.kumar@ashnik.com> wrote:
On Tue, Aug 16, 2016 at 1:10 PM James Sewell <james.sewell@jirotech.com> wrote:Hey,
I understand that.But a hot standby should always be ready to promote (given it originally caught up) right?I think it's a moot point really as some sort of corruption has been introduced, the machines still won't wouldn't start after they could see the archive destination again.Did you had a pending basebackup on the standby or a start backup (with no matching stop backup)?Was there a crash/immediate shutdown on the standby during this network outage? Do you have full page writes/fsync disabled?Cheers,James Sewell,Solutions ArchitectSuite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009On Tue, Aug 16, 2016 at 12:36 PM, John R Pierce <pierce@hogranch.com> wrote:On 8/15/2016 7:23 PM, James Sewell wrote:Those are all good questions.
Essentially this is a situation where DR is network separated from Prod - so I would expect the archive command to fail. I'll have to check the script it must not be passing the error back through to PostgreSQL.
This still shouldn't cause database corruption though right? - it's just not getting WALs.
if the slave database is asking for the WAL's, it needs them. if it needs them and can't get them, then it can't catch up and start.
--
john r pierce, recycling bits in santa cruz
--
Sent via pgsql-general mailing list (pgsql-general@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-general
The contents of this email are confidential and may be subject to legal or professional privilege and copyright. No representation is made that this email is free of viruses or other defects. If you have received this communication in error, you may not copy or distribute any part of it or otherwise disclose its contents to anyone. Please advise the sender of your incorrect receipt of this correspondence.----Best RegardsSameer Kumar | DB Solution ArchitectASHNIK PTE. LTD.101 Cecil Street, #11-11 Tong Eng Building, Singapore 069 533
T: +65 6438 3504 | M: +65 8110 0350
Skype: sameer.ashnik | www.
ashnik.com
The contents of this email are confidential and may be subject to legal or professional privilege and copyright. No representation is made that this email is free of viruses or other defects. If you have received this communication in error, you may not copy or distribute any part of it or otherwise disclose its contents to anyone. Please advise the sender of your incorrect receipt of this correspondence.
On 16 August 2016 at 08:11, James Sewell <james.sewell@jirotech.com> wrote:
--
As per the logs there was a crash of one standby, which seems to have corrupted that standby and the two cascading standby.
- No backups
- Full page writes enabled
- Fsync enabled
WAL records are CRC checked, so it may just be a bug, not corruption that affects multiple servers.
At the moment we know the Startup process died, but we don't know why.
Do you repeatedly get this error?
Please set log_error_verbosity = VERBOSE and rerun
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
And a diagram of how it hangs together.
Cheers,
James Sewell,
PostgreSQL Team Lead / Solutions Architect
Suite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009
On Sat, Aug 13, 2016 at 7:54 AM, James Sewell <james.sewell@jirotech.com> wrote:
(from other thread)
- 9.5.3
- Redhat 7.2 on VMWare
- Single PostgreSQL instance one each machine
- Every machine in DR became corrupt, so interestingly this must have been sent to the two cascading nodes via WAL before the crash on the hub DR node
- No OS logs indicating anything abnormal
I think the key looks like the (legitimate) loss of network to the Prod master, then:(0:XX000)FATAL: invalid memory alloc request size 3445219328Everything seems to go wrong from there. Are WAL segments checked for integrity once they are received?James Sewell,PostgreSQL Team Lead / Solutions ArchitectSuite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009On Sat, Aug 13, 2016 at 7:43 AM, James Sewell <james.sewell@jirotech.com> wrote: It's on 9.5.3.I've actually created this mail twice (I sent once as an unregistered address and assumed it would be dropped). I sent a diagram to the other one, I'll forward that mail here now for completeness.Cheers,James Sewell,PostgreSQL Team Lead / Solutions ArchitectSuite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009On Sat, Aug 13, 2016 at 5:20 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: James Sewell wrote:
> 2016-08-12 04:43:53 GMT [23614]: [5-1] user=,db=,client= (0:00000)LOG: consistent recovery state reached at 3/8811DFF0
> 2016-08-12 04:43:53 GMT [23614]: [6-1] user=,db=,client= (0:XX000)FATAL: invalid memory alloc request size 3445219328
> 2016-08-12 04:43:53 GMT [23612]: [3-1] user=,db=,client= (0:00000)LOG: database system is ready to accept read only connections
> 2016-08-12 04:43:53 GMT [23612]: [4-1] user=,db=,client= (0:00000)LOG: startup process (PID 23614) exited with exit code 1
> 2016-08-12 04:43:53 GMT [23612]: [5-1] user=,db=,client= (0:00000)LOG: terminating any other active server processes
> 2016-08-12 04:43:53 GMT [23612]: [6-1] user=,db=,client= (0:00000)LOG: archiver process (PID 23627) exited with exit code 1
What version is this?
Hm, so the startup process finds the consistent point (which signals
postmaster so that line 23612/3 says "ready to accept read-only conns")
and immediately dies because of the invalid memory alloc error. I
suppose that error must be while trying to process some xlog record, but
without a xlog address it's difficult to say anything. I suppose you
could try to pg_xlogdump WAL starting at the last known good address
3/8811DFF0 but I wouldn't know what to look for.
One strange thing is that xlog replay sets up an error context, so you
would have had a line like "xlog redo HEAP" etc, but there's nothing
here. So maybe the allocation is not exactly in xlog replay, but
something different. We'd need to see a backtrace in order to see what.
Since this occurs in the startup process, probably the easiest way is to
patch the source to turn that error into PANIC, then re-run and examine
the resulting core file.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & ServicesJames Sewell,PostgreSQL Team Lead / Solutions ArchitectSuite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009On Sat, Aug 13, 2016 at 5:20 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote:James Sewell wrote:
> 2016-08-12 04:43:53 GMT [23614]: [5-1] user=,db=,client= (0:00000)LOG: consistent recovery state reached at 3/8811DFF0
> 2016-08-12 04:43:53 GMT [23614]: [6-1] user=,db=,client= (0:XX000)FATAL: invalid memory alloc request size 3445219328
> 2016-08-12 04:43:53 GMT [23612]: [3-1] user=,db=,client= (0:00000)LOG: database system is ready to accept read only connections
> 2016-08-12 04:43:53 GMT [23612]: [4-1] user=,db=,client= (0:00000)LOG: startup process (PID 23614) exited with exit code 1
> 2016-08-12 04:43:53 GMT [23612]: [5-1] user=,db=,client= (0:00000)LOG: terminating any other active server processes
> 2016-08-12 04:43:53 GMT [23612]: [6-1] user=,db=,client= (0:00000)LOG: archiver process (PID 23627) exited with exit code 1
What version is this?
Hm, so the startup process finds the consistent point (which signals
postmaster so that line 23612/3 says "ready to accept read-only conns")
and immediately dies because of the invalid memory alloc error. I
suppose that error must be while trying to process some xlog record, but
without a xlog address it's difficult to say anything. I suppose you
could try to pg_xlogdump WAL starting at the last known good address
3/8811DFF0 but I wouldn't know what to look for.
One strange thing is that xlog replay sets up an error context, so you
would have had a line like "xlog redo HEAP" etc, but there's nothing
here. So maybe the allocation is not exactly in xlog replay, but
something different. We'd need to see a backtrace in order to see what.
Since this occurs in the startup process, probably the easiest way is to
patch the source to turn that error into PANIC, then re-run and examine
the resulting core file.
--
Álvaro Herrera http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
The contents of this email are confidential and may be subject to legal or professional privilege and copyright. No representation is made that this email is free of viruses or other defects. If you have received this communication in error, you may not copy or distribute any part of it or otherwise disclose its contents to anyone. Please advise the sender of your incorrect receipt of this correspondence.
Attachment
{kind=link}
Hi,
No, this was a one off in a network split situation.
I'll check the startup when I get a chance - thanks for the help.
Cheers,
James Sewell,
Solutions Architect
Suite 112, Jones Bay Wharf, 26-32 Pirrama Road, Pyrmont NSW 2009
On Tue, Aug 16, 2016 at 5:55 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
On 16 August 2016 at 08:11, James Sewell <james.sewell@jirotech.com> wrote:--As per the logs there was a crash of one standby, which seems to have corrupted that standby and the two cascading standby.
- No backups
- Full page writes enabled
- Fsync enabled
WAL records are CRC checked, so it may just be a bug, not corruption that affects multiple servers.At the moment we know the Startup process died, but we don't know why.Do you repeatedly get this error?Please set log_error_verbosity = VERBOSE and rerunSimon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
The contents of this email are confidential and may be subject to legal or professional privilege and copyright. No representation is made that this email is free of viruses or other defects. If you have received this communication in error, you may not copy or distribute any part of it or otherwise disclose its contents to anyone. Please advise the sender of your incorrect receipt of this correspondence.
On Mon, Aug 15, 2016 at 7:23 PM, James Sewell <james.sewell@jirotech.com> wrote:
Those are all good questions.Essentially this is a situation where DR is network separated from Prod - so I would expect the archive command to fail.
archive_command or restore_command? I thought it was restore_command.
I'll have to check the script it must not be passing the error back through to PostgreSQL.This still shouldn't cause database corruption though right? - it's just not getting WALs.
If the WAL it does have is corrupt, and it can't replace that with a good copy because the command is failing, then what else is it going to do?
If the original WAL transfer got interrupted mid-stream, then you will have a bad record in the middle of the WAL. If by some spectacular stroke of bad luck, the CRC checksum on that bad record happens to collide, then it will try to decode that bad record.
Cheers,
Jeff