Thread: CLOG contention
A few weeks ago I posted some performance results showing that increasing NUM_CLOG_BUFFERS was improving pgbench performance. http://archives.postgresql.org/pgsql-hackers/2011-12/msg00095.php I spent some time today looking at this in a bit more detail. Somewhat obviously in retrospect, it turns out that the problem becomes more severe the longer you run the test. CLOG lookups are induced when we go to update a row that we've previously updated. When the test first starts, just after pgbench -i, all the rows are hinted and, even if they weren't, they all have the same XID. So no problem. But, as the fraction of rows that have been updated increases, it becomes progressively more likely that the next update will hit a row that's already been updated. Initially, that's OK, because we can keep all the CLOG pages of interest in the 8 available buffers. But eaten through enough XIDs - specifically, 8 buffers * 8192 bytes/buffer * 4 xids/byte = 256k - we can't keep all the necessary pages in memory at the same time, and so we have to keep replacing CLOG pages. This effect is not difficult to see even on my 2-core laptop, although I'm not sure whether it causes any material performance degradation. If you have enough concurrent tasks, a probably-more-serious form of starvation can occur. As SlruSelectLRUPage notes: /* * We need to wait for I/O. Normal case is that it's dirty and we * must initiate a write, but it's possible that the page is already * write-busy, or in the worst case still read-busy. In those cases * we wait for the existing I/O to complete. */ On Nate Boley's 32-core box, after running pgbench for a few minutes, that "in the worst case" scenario starts happening quite regularly, apparently because the number of people who simultaneously wish to read a different CLOG pages exceeds the number of available buffers into which they can be read. The ninth and following backends to come along have to wait until the least-recently-used page is no longer read-busy before starting their reads. So, what do we do about this? The obvious answer is "increase NUM_CLOG_BUFFERS", and I'm not sure that's a bad idea. 64kB is a pretty small cache on anything other than an embedded system, these days. We could either increase the hard-coded value, or make it configurable - but it would have to be PGC_POSTMASTER, since there's no way to allocate more shared memory later on. The downsides of this approach are: 1. If we make it configurable, nobody will have a clue what value to set. 2. If we just make it bigger, people laboring under the default 32MB shared memory limit will conceivably suffer even more than they do now if they just initdb and go. A more radical approach would be to try to merge the buffer arenas for the various SLRUs either with each other or with shared_buffers, which would presumably allow a lot more flexibility to ratchet the number of CLOG buffers up or down depending on overall memory pressure. Merging the buffer arenas into shared_buffers seems like the most flexible solution, but it also seems like a big, complex, error-prone behavior change, because the SLRU machinery does things quite differently from shared_buffers: we look up buffers with a linear array search rather than a hash table probe; we have only a per-SLRU lock and a per-page lock, rather than separate mapping locks, content locks, io-in-progress locks, and pins; and while the main buffer manager is content with some loosey-goosey approximation of recency, the SLRU code makes a fervent attempt at strict LRU (slightly compromised for the sake of reduced locking in SimpleLruReadPage_Readonly). Any thoughts on what makes most sense here? I find it fairly tempting to just crank up NUM_CLOG_BUFFERS and call it good, but the siren song of refactoring is whispering in my other ear. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> So, what do we do about this? The obvious answer is "increase
> NUM_CLOG_BUFFERS", and I'm not sure that's a bad idea.
As you say, that's likely to hurt people running in small shared
memory. I too have thought about merging the SLRU areas into the main
shared buffer arena, and likewise have concluded that it is likely to
be way more painful than it's worth. What I think might be an
appropriate compromise is something similar to what we did for
autotuning wal_buffers: use a fixed percentage of shared_buffers, with
some minimum and maximum limits to ensure sanity. But picking the
appropriate percentage would take a bit of research.
regards, tom lane
Robert Haas <robertmhaas@gmail.com> writes:
> ... while the main buffer manager is
> content with some loosey-goosey approximation of recency, the SLRU
> code makes a fervent attempt at strict LRU (slightly compromised for
> the sake of reduced locking in SimpleLruReadPage_Readonly).
Oh btw, I haven't looked at that code recently, but I have a nasty
feeling that there are parts of it that assume that the number of
buffers it is managing is fairly small. Cranking up the number
might require more work than just changing the value.
regards, tom lane
On Wed, Dec 21, 2011 at 5:33 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> ... while the main buffer manager is >> content with some loosey-goosey approximation of recency, the SLRU >> code makes a fervent attempt at strict LRU (slightly compromised for >> the sake of reduced locking in SimpleLruReadPage_Readonly). > > Oh btw, I haven't looked at that code recently, but I have a nasty > feeling that there are parts of it that assume that the number of > buffers it is managing is fairly small. Cranking up the number > might require more work than just changing the value. My memory was that you'd said benchmarks showed NUM_CLOG_BUFFERS needs to be low enough to allow fast lookups, since the lookups don't use an LRU they just scan all buffers. Indeed, it was your objection that stopped NUM_CLOG_BUFFERS being increased many years before this. With the increased performance we have now, I don't think increasing that alone will be that useful since it doesn't solve all of the problems and (I am told) likely increases lookup speed. The full list of clog problems I'm aware of is: raw lookup speed, multi-user contention, writes at checkpoint and new xid allocation. Would it be better just to have multiple SLRUs dedicated to the clog? Simply partition things so we have 2^N sets of everything, and we look up the xid in partition (xid % (2^N)). That would overcome all of the problems, not just lookup, in exactly the same way that we partitioned the buffer and lock manager. We would use a graduated offset on the page to avoid zeroing pages at the same time. Clog size wouldn't increase, we'd have the same number of bits, just spread across 2^N files. We'd have more pages too, but that's not a bad thing since it spreads out the contention. Code-wise, those changes would be isolated to clog.c only, probably a days work if you like the idea. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Dec 21, 2011 at 12:33 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Oh btw, I haven't looked at that code recently, but I have a nasty > feeling that there are parts of it that assume that the number of > buffers it is managing is fairly small. Cranking up the number > might require more work than just changing the value. Oh, you mean like the fact that it tries to do strict LRU page replacement? *rolls eyes* We seem to have named the SLRU system after one of its scalability limitations... I think there probably are some scalability limits to the current implementation, but also I think we could probably increase the current value modestly with something less than a total rewrite. Linearly scanning the slot array won't scale indefinitely, but I think it will scale to more than 8 elements. The performance results I posted previously make it clear that 8 -> 32 is a net win at least on that system. One fairly low-impact option might be to make the cache less than fully associative - e.g. given N buffers, a page with pageno % 4 == X is only allowed to be in a slot numbered between (N/4)*X and (N/4)*(X+1)-1. That likely would be counterproductive at N = 8 but might be OK at larger values. We could also switch to using a hash table but that seems awfully heavy-weight. The real question is how to decide how many buffers to create. You suggested a formula based on shared_buffers, but what would that formula be? I mean, a typical large system is going to have 1,048,576 shared buffers, and it probably needs less than 0.1% of that amount of CLOG buffers. My guess is that there's no real reason to skimp: if you are really tight for memory, you might want to crank this down, but otherwise you may as well just go with whatever we decide the best-performing value is. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Dec 21, 2011 at 5:17 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > With the increased performance we have now, I don't think increasing > that alone will be that useful since it doesn't solve all of the > problems and (I am told) likely increases lookup speed. I have benchmarks showing that it works, for whatever that's worth. > The full list of clog problems I'm aware of is: raw lookup speed, > multi-user contention, writes at checkpoint and new xid allocation. What is the best workload to show a bottleneck on raw lookup speed? I wouldn't expect writes at checkpoint to be a big problem because it's so little data. What's the problem with new XID allocation? > Would it be better just to have multiple SLRUs dedicated to the clog? > Simply partition things so we have 2^N sets of everything, and we look > up the xid in partition (xid % (2^N)). That would overcome all of the > problems, not just lookup, in exactly the same way that we partitioned > the buffer and lock manager. We would use a graduated offset on the > page to avoid zeroing pages at the same time. Clog size wouldn't > increase, we'd have the same number of bits, just spread across 2^N > files. We'd have more pages too, but that's not a bad thing since it > spreads out the contention. It seems that would increase memory requirements (clog1 through clog4 with 2 pages each doesn't sound workable). It would also break on-disk compatibility for pg_upgrade. I'm still holding out hope that we can find a simpler solution... -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> wrote: > Any thoughts on what makes most sense here? I find it fairly > tempting to just crank up NUM_CLOG_BUFFERS and call it good, The only thought I have to add to discussion so far is that the need to do anything may be reduced significantly by any work to write hint bits more aggressively. We only consult CLOG for tuples on which hint bits have not yet been set, right? What if, before writing a page, we try to set hint bits where we can? When successful, it would not only prevent one or more later writes of the page, but could also prevent having to load old CLOG pages. Perhaps the hint bit issue should be addressed first, and *then* we check whether we still have a problem with CLOG. -Kevin
On Wed, Dec 21, 2011 at 10:51 AM, Kevin Grittner <Kevin.Grittner@wicourts.gov> wrote: > Robert Haas <robertmhaas@gmail.com> wrote: >> Any thoughts on what makes most sense here? I find it fairly >> tempting to just crank up NUM_CLOG_BUFFERS and call it good, > > The only thought I have to add to discussion so far is that the need > to do anything may be reduced significantly by any work to write > hint bits more aggressively. We only consult CLOG for tuples on > which hint bits have not yet been set, right? What if, before > writing a page, we try to set hint bits where we can? When > successful, it would not only prevent one or more later writes of > the page, but could also prevent having to load old CLOG pages. > Perhaps the hint bit issue should be addressed first, and *then* we > check whether we still have a problem with CLOG. There may be workloads where that will help, but it's definitely not going to cover all cases. Consider my trusty pgbench-at-scale-factor-100 test case: since the working set fits inside shared buffers, we're only writing pages at checkpoint time. The contention happens because we randomly select rows from the table, and whatever row we select hasn't been examined since it was last updated, and so it's unhinted. But we're not reading the page in: it's already in shared buffers, and has never been written out. I don't see any realistic way to avoid the CLOG lookups in that case: nobody else has had any reason to touch that page in any way since the tuple was first written. So I think we need a more general solution. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Excerpts from Robert Haas's message of mié dic 21 13:18:36 -0300 2011: > There may be workloads where that will help, but it's definitely not > going to cover all cases. Consider my trusty > pgbench-at-scale-factor-100 test case: since the working set fits > inside shared buffers, we're only writing pages at checkpoint time. > The contention happens because we randomly select rows from the table, > and whatever row we select hasn't been examined since it was last > updated, and so it's unhinted. But we're not reading the page in: > it's already in shared buffers, and has never been written out. I > don't see any realistic way to avoid the CLOG lookups in that case: > nobody else has had any reason to touch that page in any way since the > tuple was first written. Maybe we need a background "tuple hinter" process ... -- Álvaro Herrera <alvherre@commandprompt.com> The PostgreSQL Company - Command Prompt, Inc. PostgreSQL Replication, Consulting, Custom Development, 24x7 support
Robert Haas <robertmhaas@gmail.com> writes:
> I think there probably are some scalability limits to the current
> implementation, but also I think we could probably increase the
> current value modestly with something less than a total rewrite.
> Linearly scanning the slot array won't scale indefinitely, but I think
> it will scale to more than 8 elements. The performance results I
> posted previously make it clear that 8 -> 32 is a net win at least on
> that system.
Agreed, the question is whether 32 is enough to fix the problem for
anything except this one benchmark.
> One fairly low-impact option might be to make the cache
> less than fully associative - e.g. given N buffers, a page with pageno
> % 4 == X is only allowed to be in a slot numbered between (N/4)*X and
> (N/4)*(X+1)-1. That likely would be counterproductive at N = 8 but
> might be OK at larger values.
I'm inclined to think that that specific arrangement wouldn't be good.
The normal access pattern for CLOG is, I believe, an exponentially
decaying probability-of-access for each page as you go further back from
current. We have a hack to pin the current (latest) page into SLRU all
the time, but you want the design to be such that the next-to-latest
page is most likely to still be around, then the second-latest, etc.
If I'm reading your equation correctly then the most recent pages would
compete against each other, not against much older pages, which is
exactly the wrong thing. Perhaps what you actually meant to say was
that all pages with the same number mod 4 are in one bucket, which would
be better, but still not really ideal: for instance the next-to-latest
page could end up getting removed while say the third-latest page is
still there because it's in a different associative bucket that's under
less pressure.
But possibly we could fix that with some other variant of the idea.
I certainly agree that strict LRU isn't an essential property here,
so long as we have a design that is matched to the expected access
pattern statistics.
> We could also switch to using a hash
> table but that seems awfully heavy-weight.
Yeah. If we're not going to go to hundreds of CLOG buffers, which
I think probably wouldn't be useful, then hashing is unlikely to be the
best answer.
> The real question is how to decide how many buffers to create. You
> suggested a formula based on shared_buffers, but what would that
> formula be? I mean, a typical large system is going to have 1,048,576
> shared buffers, and it probably needs less than 0.1% of that amount of
> CLOG buffers.
Well, something like "0.1% with minimum of 8 and max of 32" might be
reasonable. What I'm mainly fuzzy about is the upper limit.
regards, tom lane
On Wed, Dec 21, 2011 at 3:28 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Dec 21, 2011 at 5:17 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >> With the increased performance we have now, I don't think increasing >> that alone will be that useful since it doesn't solve all of the >> problems and (I am told) likely increases lookup speed. > > I have benchmarks showing that it works, for whatever that's worth. > >> The full list of clog problems I'm aware of is: raw lookup speed, >> multi-user contention, writes at checkpoint and new xid allocation. > > What is the best workload to show a bottleneck on raw lookup speed? A microbenchmark. > I wouldn't expect writes at checkpoint to be a big problem because > it's so little data. > > What's the problem with new XID allocation? Earlier experience shows that those are areas of concern. You aren't measuring response time in your tests, so you won't notice them as problems. But they do effect throughput much more than intuition says it would. >> Would it be better just to have multiple SLRUs dedicated to the clog? >> Simply partition things so we have 2^N sets of everything, and we look >> up the xid in partition (xid % (2^N)). That would overcome all of the >> problems, not just lookup, in exactly the same way that we partitioned >> the buffer and lock manager. We would use a graduated offset on the >> page to avoid zeroing pages at the same time. Clog size wouldn't >> increase, we'd have the same number of bits, just spread across 2^N >> files. We'd have more pages too, but that's not a bad thing since it >> spreads out the contention. > > It seems that would increase memory requirements (clog1 through clog4 > with 2 pages each doesn't sound workable). It would also break > on-disk compatibility for pg_upgrade. I'm still holding out hope that > we can find a simpler solution... Not sure what you mean by "increase memory requirements". How would increasing NUM_CLOG_BUFFERS = 64 differ from having NUM_CLOG_BUFFERS = 8 and NUM_CLOG_PARTITIONS = 8? I think you appreciate that having 8 lwlocks rather than 1 might help scalability. I'm sure pg_upgrade can be tweaked easily enough and it would still work quickly. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Dec 21, 2011 at 11:48 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Agreed, the question is whether 32 is enough to fix the problem for > anything except this one benchmark. Right. My thought on that topic is that it depends on what you mean by "fix". It's clearly NOT possible to keep enough CLOG buffers around to cover the entire range of XID space that might get probed, at least not without some massive rethinking of the infrastructure. It seems that the amount of space that might need to be covered there is at least on the order of vacuum_freeze_table_age, which is to say 150 million by default. At 32K txns/page, that would require almost 5K pages, which is a lot more than 8. On the other hand, if we just want to avoid having more requests simultaneously in flight than we have buffers, so that backends don't need to wait for an available buffer before beginning their I/O, then something on the order of the number of CPUs in the machine is likely sufficient. I'll do a little more testing and see if I can figure out where the tipping point is on this 32-core box. >> One fairly low-impact option might be to make the cache >> less than fully associative - e.g. given N buffers, a page with pageno >> % 4 == X is only allowed to be in a slot numbered between (N/4)*X and >> (N/4)*(X+1)-1. That likely would be counterproductive at N = 8 but >> might be OK at larger values. > > I'm inclined to think that that specific arrangement wouldn't be good. > The normal access pattern for CLOG is, I believe, an exponentially > decaying probability-of-access for each page as you go further back from > current. We have a hack to pin the current (latest) page into SLRU all > the time, but you want the design to be such that the next-to-latest > page is most likely to still be around, then the second-latest, etc. > > If I'm reading your equation correctly then the most recent pages would > compete against each other, not against much older pages, which is > exactly the wrong thing. Perhaps what you actually meant to say was > that all pages with the same number mod 4 are in one bucket, which would > be better, That's what I meant. I think the formula works out to that, but in any case it's what I meant. :-) > but still not really ideal: for instance the next-to-latest > page could end up getting removed while say the third-latest page is > still there because it's in a different associative bucket that's under > less pressure. Well, sure. But who is to say that's bad? I think you can find a way to throw stones at any given algorithm we might choose to implement. For example, if you contrive things so that you repeatedly access the same old CLOG pages cyclically: 1,2,3,4,5,6,7,8,1,2,3,4,5,6,7,8,... ...then our existing LRU algorithm will be anti-optimal, because we'll keep the latest page plus the most recently accessed 7 old pages in memory, and every lookup will fault out the page that the next lookup is about to need. If you're not that excited about that happening in real life, neither am I. But neither am I that excited about your scenario: if the next-to-last page gets kicked out, there are a whole bunch of pages -- maybe 8, if you imagine 32 buffers split 4 ways -- that have been accessed more recently than that next-to-last page. So it wouldn't be resident in an 8-buffer pool either. Maybe the last page was mostly transactions updating some infrequently-accessed table, and we don't really need that page right now. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Wed, Dec 21, 2011 at 11:48 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> I'm inclined to think that that specific arrangement wouldn't be good.
>> The normal access pattern for CLOG is, I believe, an exponentially
>> decaying probability-of-access for each page as you go further back from
>> current. ... for instance the next-to-latest
>> page could end up getting removed while say the third-latest page is
>> still there because it's in a different associative bucket that's under
>> less pressure.
> Well, sure. But who is to say that's bad? I think you can find a way
> to throw stones at any given algorithm we might choose to implement.
The point I'm trying to make is that buffer management schemes like
that one are built on the assumption that the probability of access is
roughly uniform for all pages. We know (or at least have strong reason
to presume) that CLOG pages have very non-uniform probability of access.
The straight LRU scheme is good because it deals well with non-uniform
access patterns. Dividing the buffers into independent buckets in a way
that doesn't account for the expected access probabilities is going to
degrade things. (The approach Simon suggests nearby seems isomorphic to
yours and so suffers from this same objection, btw.)
> For example, if you contrive things so that you repeatedly access the
> same old CLOG pages cyclically: 1,2,3,4,5,6,7,8,1,2,3,4,5,6,7,8,...
Sure, and the reason that that's contrived is that it flies in the face
of reasonable assumptions about CLOG access probabilities. Any scheme
will lose some of the time, but you don't want to pick a scheme that is
more likely to lose for more probable access patterns.
It strikes me that one simple thing we could do is extend the current
heuristic that says "pin the latest page". That is, pin the last K
pages into SLRU, and apply LRU or some other method across the rest.
If K is large enough, that should get us down to where the differential
in access probability among the older pages is small enough to neglect,
and then we could apply associative bucketing or other methods to the
rest without fear of getting burnt by the common usage pattern. I don't
know what K would need to be, though. Maybe it's worth instrumenting
a benchmark run or two so we can get some facts rather than guesses
about the access frequencies?
regards, tom lane
On Wed, Dec 21, 2011 at 1:09 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > It strikes me that one simple thing we could do is extend the current > heuristic that says "pin the latest page". That is, pin the last K > pages into SLRU, and apply LRU or some other method across the rest. > If K is large enough, that should get us down to where the differential > in access probability among the older pages is small enough to neglect, > and then we could apply associative bucketing or other methods to the > rest without fear of getting burnt by the common usage pattern. I don't > know what K would need to be, though. Maybe it's worth instrumenting > a benchmark run or two so we can get some facts rather than guesses > about the access frequencies? I guess the point is that it seems to me to depend rather heavily on what benchmark you run. For something like pgbench, we initialize the cluster with one or a few big transactions, so the page containing those XIDs figures to stay hot for a very long time. Then after that we choose rows to update randomly, which will produce the sort of newer-pages-are-hotter-than-older-pages effect that you're talking about. But the slope of the curve depends heavily on the scale factor. If we have scale factor 1 (= 100,000 rows) then chances are that when we randomly pick a row to update, we'll hit one that's been touched within the last few hundred thousand updates - i.e. the last couple of CLOG pages. But if we have scale factor 100 (= 10,000,000 rows) we might easily hit a row that hasn't been updated for many millions of transactions, so there's going to be a much longer tail there. And some other test could yield very different results - e.g. something that uses lots of subtransactions might well have a much longer tail, while something that does more than one update per transaction would presumably have a shorter one. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Dec 21, 2011 at 3:24 PM, Robert Haas <robertmhaas@gmail.com> wrote: > I think there probably are some scalability limits to the current > implementation, but also I think we could probably increase the > current value modestly with something less than a total rewrite. > Linearly scanning the slot array won't scale indefinitely, but I think > it will scale to more than 8 elements. The performance results I > posted previously make it clear that 8 -> 32 is a net win at least on > that system. Agreed to that, but I don't think its nearly enough. > One fairly low-impact option might be to make the cache > less than fully associative - e.g. given N buffers, a page with pageno > % 4 == X is only allowed to be in a slot numbered between (N/4)*X and > (N/4)*(X+1)-1. That likely would be counterproductive at N = 8 but > might be OK at larger values. Which is pretty much the same as saying, yes, lets partition the clog as I suggested, but by a different route. > We could also switch to using a hash > table but that seems awfully heavy-weight. Which is a re-write of SLRU ground up and inapproriate for most SLRU usage. We'd get partitioning "for free" as long as we re-write. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Dec 21, 2011 at 2:05 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > On Wed, Dec 21, 2011 at 3:24 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> I think there probably are some scalability limits to the current >> implementation, but also I think we could probably increase the >> current value modestly with something less than a total rewrite. >> Linearly scanning the slot array won't scale indefinitely, but I think >> it will scale to more than 8 elements. The performance results I >> posted previously make it clear that 8 -> 32 is a net win at least on >> that system. > > Agreed to that, but I don't think its nearly enough. > >> One fairly low-impact option might be to make the cache >> less than fully associative - e.g. given N buffers, a page with pageno >> % 4 == X is only allowed to be in a slot numbered between (N/4)*X and >> (N/4)*(X+1)-1. That likely would be counterproductive at N = 8 but >> might be OK at larger values. > > Which is pretty much the same as saying, yes, lets partition the clog > as I suggested, but by a different route. > >> We could also switch to using a hash >> table but that seems awfully heavy-weight. > > Which is a re-write of SLRU ground up and inapproriate for most SLRU > usage. We'd get partitioning "for free" as long as we re-write. I'm not sure what your point is here. I feel like this is on the edge of turning into an argument, and if we're going to have an argument I'd like to know what we're arguing about. I am not arguing that under no circumstances should we partition anything related to CLOG, nor am I trying to deny you credit for your ideas. I'm merely saying that the specific plan of having multiple SLRUs for CLOG doesn't appeal to me -- mostly because I think it will make life difficult for pg_upgrade without any compensating advantage. If we're going to go that route, I'd rather build something into the SLRU machinery generally that allows for the cache to be less than fully-associative, with all of the savings in terms of lock contention that this entails.Such a system could be used by any SLRU, not just CLOG,if it proved to be helpful; and it would avoid any on-disk changes, with, as far as I can see, basically no downside. That having been said, Tom isn't convinced that any form of partitioning is the right way to go, and since Tom often has good ideas, I'd like to explore his notions of how we might fix this problem other than via some form of partitioning before we focus in on partitioning. Partitioning may ultimately be the right way to go, but let's keep an open mind: this thread is only 14 hours old. The only things I'm completely convinced of at this point are (1) we need more CLOG buffers (but I don't know exactly how many) and (2) the current code isn't designed to manage large numbers of buffers (but I don't know exactly where it starts to fall over). If I'm completely misunderstanding the point of your email, please set me straight (gently). Thanks, -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Dec 21, 2011 at 12:48 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On the other hand, if we just want to avoid having more requests > simultaneously in flight than we have buffers, so that backends don't > need to wait for an available buffer before beginning their I/O, then > something on the order of the number of CPUs in the machine is likely > sufficient. I'll do a little more testing and see if I can figure out > where the tipping point is on this 32-core box. I recompiled with NUM_CLOG_BUFFERS = 8, 16, 24, 32, 40, 48 and ran 5-minute tests, using unlogged tables to avoid getting killed by WALInsertLock contentions. With 32-clients on this 32-core box, the tipping point is somewhere in the neighborhood of 32 buffers. 40 buffers might still be winning over 32, or maybe not, but 48 is definitely losing. Below 32, more is better, all the way up. Here are the full results: resultswu.clog16.32.100.300:tps = 19549.454462 (including connections establishing) resultswu.clog16.32.100.300:tps = 19883.583245 (including connections establishing) resultswu.clog16.32.100.300:tps = 19984.857186 (including connections establishing) resultswu.clog24.32.100.300:tps = 20124.147651 (including connections establishing) resultswu.clog24.32.100.300:tps = 20108.504407 (including connections establishing) resultswu.clog24.32.100.300:tps = 20303.964120 (including connections establishing) resultswu.clog32.32.100.300:tps = 20573.873097 (including connections establishing) resultswu.clog32.32.100.300:tps = 20444.289259 (including connections establishing) resultswu.clog32.32.100.300:tps = 20234.209965 (including connections establishing) resultswu.clog40.32.100.300:tps = 21762.222195 (including connections establishing) resultswu.clog40.32.100.300:tps = 20621.749677 (including connections establishing) resultswu.clog40.32.100.300:tps = 20290.990673 (including connections establishing) resultswu.clog48.32.100.300:tps = 19253.424997 (including connections establishing) resultswu.clog48.32.100.300:tps = 19542.095191 (including connections establishing) resultswu.clog48.32.100.300:tps = 19284.962036 (including connections establishing) resultswu.master.32.100.300:tps = 18694.886622 (including connections establishing) resultswu.master.32.100.300:tps = 18417.647703 (including connections establishing) resultswu.master.32.100.300:tps = 18331.718955 (including connections establishing) Parameters in use: shared_buffers = 8GB, maintenance_work_mem = 1GB, synchronous_commit = off, checkpoint_segments = 300, checkpoint_timeout = 15min, checkpoint_completion_target = 0.9, wal_writer_delay = 20ms It isn't clear to me whether we can extrapolate anything more general from this. It'd be awfully interesting to repeat this experiment on, say, an 8-core server, but I don't have one of those I can use at the moment. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Dec 21, 2011 at 7:25 PM, Robert Haas <robertmhaas@gmail.com> wrote: > I am not arguing This seems like a normal and cool technical discussion to me here. > I'm merely saying > that the specific plan of having multiple SLRUs for CLOG doesn't > appeal to me -- mostly because I think it will make life difficult for > pg_upgrade without any compensating advantage. If we're going to go > that route, I'd rather build something into the SLRU machinery > generally that allows for the cache to be less than fully-associative, > with all of the savings in terms of lock contention that this entails. > Such a system could be used by any SLRU, not just CLOG, if it proved > to be helpful; and it would avoid any on-disk changes, with, as far as > I can see, basically no downside. Partitioning will give us more buffers and more LWlocks, to spread the contention when we access the buffers. I use that word because its what we call the technique already used in the buffer manager and lock manager. If you wish to call this "less than fully-associative" I really don't mind, as long as we're discussing the same overall concept, so we can then focus on an implementation of that concept, which no doubt has many ways of doing it. More buffers per lock does reduce the lock contention somewhat, but not by much. So for me, it seems essential that we have more LWlocks to solve the problem, which is where partitioning comes in. My perspective is that there is clog contention in many places, not just in the ones you identified. Main places I see are: * Access to older pages (identified by you upthread). More buffers addresses this problem. * Committing requires us to hold exclusive lock on a page, so there is contention from nearly all sessions for the same page. The only way to solve that is by striping pages, so that one page in the current clog architecture would be striped across N pages with consecutive xids in separate partitions. Notably this addresses Tom's concern that there is a much higher request rate on very recent pages - each page would be split into N pages, so reducing contention. * We allocate a new clog page every 32k xids. At the rates you have now measured, we will do this every 1-2 seconds. When we do this, we must allocate a new page, which means writing the LRU page, which will be dirty, since we fill 8 buffers in 16 seconds (or even 32 buffers in about a minute), yet only flush buffers at checkpoint every 5 minutes. We then need to write an XLogRecord for the new page. All of that happens while we have the XidGenLock held. Also, while this is happening nothing can commit, or check clog. That causes nearly all work to halt for about a second, perhaps longer while the traffic queue clears. More obvious when writing to logged tables, since the XLogInsert for the new clog page is then very badly contended. If we partition then we will be able to continue accessing most of the clog pages. So I think we need * more buffers * clog page striping * partitioning And I would characterise what I am suggesting as "partitioning + striping" with the free benefit that we increase the number of buffers as well via partitioning. With all of that in mind, its relatively easy to rewrite the clog code so we allocate N SLRUs rather than just 1. That means we just touch the clog code. Striping adjacent xids onto separate pages in other ways would gut the SLRU code. We could just partition but then won't address Tom's concern, as you say. That is based upon code analysis and hacking something together while thinking - if it helps discussion I post that hack here, but its not working yet. I don't think reusing code from bufmgr/lockmgr would help either. Yes, you're right that I'm suggesting we change the clog data structures and that therefore we'd need to change pg_upgrade as well. But that seems like a relatively simple piece of code given the clear mapping between old and new structures. It would be able to run quickly at upgrade time. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Wed, Dec 21, 2011 at 4:17 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > Partitioning will give us more buffers and more LWlocks, to spread the > contention when we access the buffers. I use that word because its > what we call the technique already used in the buffer manager and lock > manager. If you wish to call this "less than fully-associative" I > really don't mind, as long as we're discussing the same overall > concept, so we can then focus on an implementation of that concept, > which no doubt has many ways of doing it. > > More buffers per lock does reduce the lock contention somewhat, but > not by much. So for me, it seems essential that we have more LWlocks > to solve the problem, which is where partitioning comes in. > > My perspective is that there is clog contention in many places, not > just in the ones you identified. Well, that's possible. The locking in slru.c is pretty screwy and could probably benefit from better locking granularity. One point worth noting is that the control lock for each SLRU protects all the SLRU buffer mappings and the contents of all the buffers; in the main buffer manager, those responsibilities are split across BufFreelistLock, 16 buffer manager partition locks, one content lock per buffer, and the buffer header spinlocks. (The SLRU per-buffer locks are the equivalent of the I/O-in-progresss locks, not the content locks.) So splitting up CLOG into multiple SLRUs might not be the only way of improving the lock granularity; the current situation is almost comical. But on the flip side, I feel like your discussion of the problems is a bit hand-wavy. I think we need some real test cases that we can look at and measure, not just an informal description of what we think is happening. I'm sure, for example, that repeatedly reading different CLOG pages costs something - but I'm not sure that it's enough to have a material impact on performance. And if it doesn't, then we'd be better off leaving it alone and working on things that do. And if it does, then we need a way to assess how successful any given approach is in addressing that problem, so we can decide which of various proposed approaches is best. > * We allocate a new clog page every 32k xids. At the rates you have > now measured, we will do this every 1-2 seconds. And a new pg_subtrans page quite a bit more frequently than that. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Dec 22, 2011 at 12:28 AM, Robert Haas <robertmhaas@gmail.com> wrote: > But on the flip side, I feel like your discussion of the problems is a > bit hand-wavy. I think we need some real test cases that we can look > at and measure, not just an informal description of what we think is > happening. I understand why you say that and take no offence. All I can say is last time I has access to a good test rig and well structured reporting and analysis I was able to see evidence of what I described to you here. I no longer have that access, which is the main reason I've not done anything in the last few years. We both know you do have good access and that's the main reason I'm telling you about it rather than just doing it myself. >> * We allocate a new clog page every 32k xids. At the rates you have >> now measured, we will do this every 1-2 seconds. > > And a new pg_subtrans page quite a bit more frequently than that. It is less of a concern, all the same. In most cases we can simply drop pg_subtrans pages (though we don't do that as often as we could), no fsync is required on write, no WAL record required for extension and no update required at commit. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
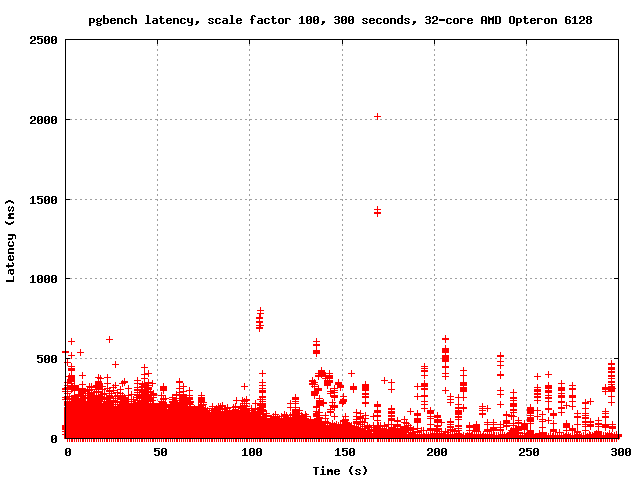
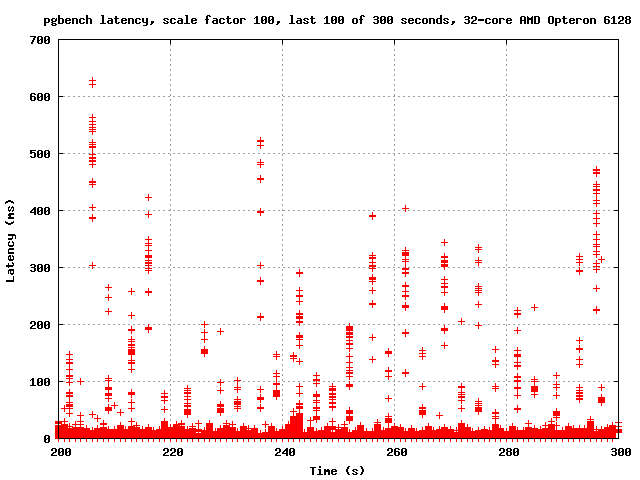
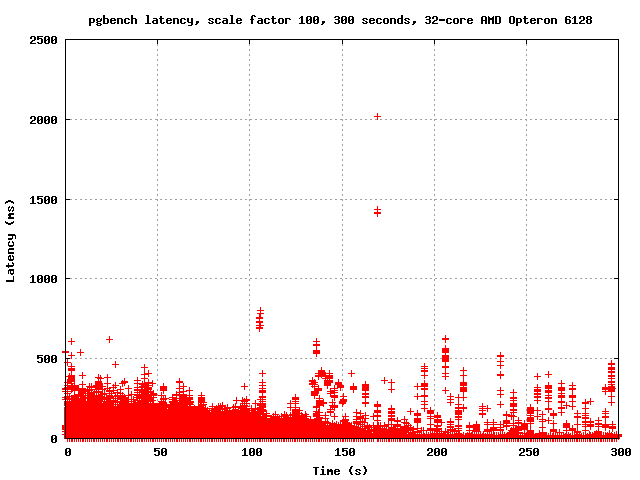
On Thu, Dec 22, 2011 at 1:04 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > I understand why you say that and take no offence. All I can say is > last time I has access to a good test rig and well structured > reporting and analysis I was able to see evidence of what I described > to you here. > > I no longer have that access, which is the main reason I've not done > anything in the last few years. We both know you do have good access > and that's the main reason I'm telling you about it rather than just > doing it myself. Right. But I need more details. If I know what to test and how to test it, I can do it. Otherwise, I'm just guessing. I dislike guessing. You mentioned "latency" so this morning I ran pgbench with -l and graphed the output. There are latency spikes every few seconds. I'm attaching the overall graph as well as the graph of the last 100 seconds, where the spikes are easier to see clearly. Now, here's the problem: it seems reasonable to hypothesize that the spikes are due to CLOG page replacement since the frequency is at least plausibly right, but this is obviously not enough to prove that conclusively. Ideas? Also, if it is that, what do we do about it? I don't think any of the ideas proposed so far are going to help much. Increasing the number of CLOG buffers isn't going to fix the problem that once they're all dirty, you have to write and fsync one before pulling in the next one. Striping might actually make it worse - everyone will move to the next buffer right around the same time, and instead of everybody waiting for one fsync, they'll each be waiting for their own. Maybe the solution is to have the background writer keep an eye on how many CLOG buffers are dirty and start writing them out if the number gets too big. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
{kind=link}
{kind=link}
On Thu, Dec 22, 2011 at 4:20 PM, Robert Haas <robertmhaas@gmail.com> wrote: > You mentioned "latency" so this morning I ran pgbench with -l and > graphed the output. There are latency spikes every few seconds. I'm > attaching the overall graph as well as the graph of the last 100 > seconds, where the spikes are easier to see clearly. Now, here's the > problem: it seems reasonable to hypothesize that the spikes are due to > CLOG page replacement since the frequency is at least plausibly right, > but this is obviously not enough to prove that conclusively. Ideas? Thanks. That illustrates the effect I explained earlier very clearly, so now we all know I wasn't speculating. > Also, if it is that, what do we do about it? I don't think any of the > ideas proposed so far are going to help much. If you don't like guessing, don't guess, don't think. Just measure. Does increasing the number of buffers solve the problems you see? That must be the first port of call - is that enough, or not? If not, we can discuss the various ideas, write patches and measure them. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Sat, Dec 24, 2011 at 9:25 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > On Thu, Dec 22, 2011 at 4:20 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> Also, if it is that, what do we do about it? I don't think any of the >> ideas proposed so far are going to help much. > > If you don't like guessing, don't guess, don't think. Just measure. > > Does increasing the number of buffers solve the problems you see? That > must be the first port of call - is that enough, or not? If not, we > can discuss the various ideas, write patches and measure them. Just in case you want a theoretical prediction to test: increasing NUM_CLOG_BUFFERS should reduce the frequency of the spikes you measured earlier. That should happen proportionally, so as that is increased they will become even less frequent. But the size of the buffer will not decrease the impact of each event when it happens. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Dec 20, 2011, at 11:29 PM, Tom Lane wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> So, what do we do about this? The obvious answer is "increase >> NUM_CLOG_BUFFERS", and I'm not sure that's a bad idea. > > As you say, that's likely to hurt people running in small shared > memory. I too have thought about merging the SLRU areas into the main > shared buffer arena, and likewise have concluded that it is likely to > be way more painful than it's worth. What I think might be an > appropriate compromise is something similar to what we did for > autotuning wal_buffers: use a fixed percentage of shared_buffers, with > some minimum and maximum limits to ensure sanity. But picking the > appropriate percentage would take a bit of research. ISTM that this is based more on number of CPUs rather than total memory, no? Likewise, things like the number of shared bufferpartitions would be highly dependent on the number of CPUs. So perhaps we should either probe the number of CPUs on a box, or have a GUC to tell us how many there are... -- Jim C. Nasby, Database Architect jim@nasby.net 512.569.9461 (cell) http://jim.nasby.net
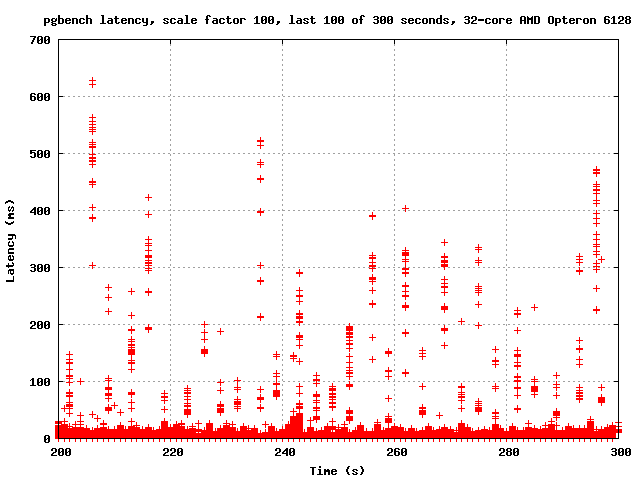
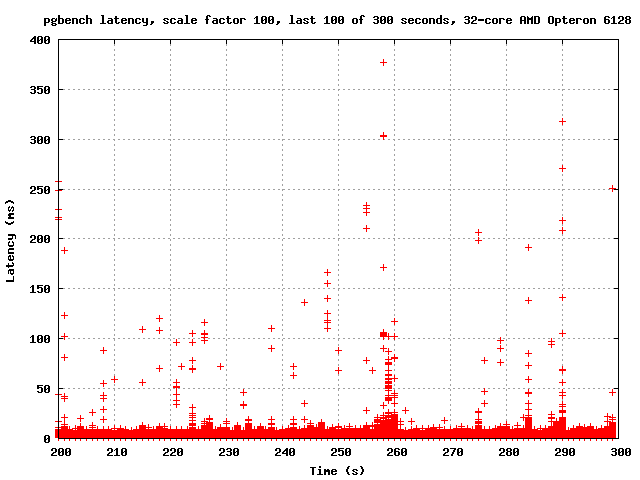
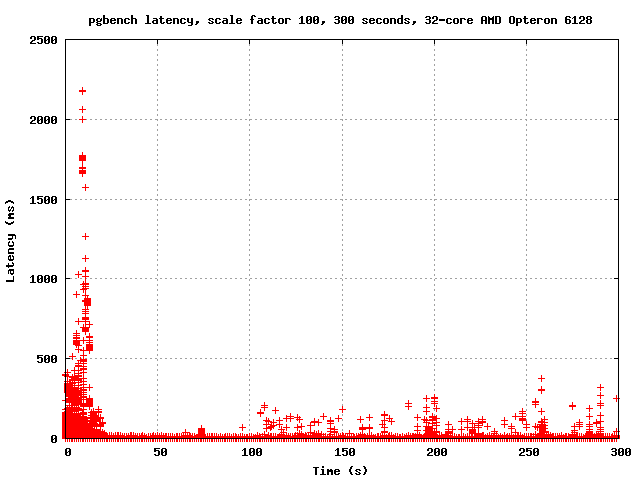
On Tue, Dec 27, 2011 at 5:23 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > On Sat, Dec 24, 2011 at 9:25 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >> On Thu, Dec 22, 2011 at 4:20 PM, Robert Haas <robertmhaas@gmail.com> wrote: > >>> Also, if it is that, what do we do about it? I don't think any of the >>> ideas proposed so far are going to help much. >> >> If you don't like guessing, don't guess, don't think. Just measure. >> >> Does increasing the number of buffers solve the problems you see? That >> must be the first port of call - is that enough, or not? If not, we >> can discuss the various ideas, write patches and measure them. > > Just in case you want a theoretical prediction to test: > > increasing NUM_CLOG_BUFFERS should reduce the frequency of the spikes > you measured earlier. That should happen proportionally, so as that is > increased they will become even less frequent. But the size of the > buffer will not decrease the impact of each event when it happens. I'm still catching up on email, so apologies for the slow response on this. I actually ran this test before Christmas, but didn't get around to emailing the results. I'm attaching graphs of the last 100 seconds of a run with the normal count of CLOG buffers, and the last 100 seconds of a run with NUM_CLOG_BUFFERS = 32. I am also attaching graphs of the entire runs. It appears to me that increasing the number of CLOG buffers reduced the severity of the latency spikes considerably. In the last 100 seconds, for example, master has several spikes in the 500-700ms range, but with 32 CLOG buffers it never goes above 400 ms. Also, the number of points associated with each spike is considerably less - each spike seems to affect fewer transactions. So it seems that at least on this machine, increasing the number of CLOG buffers both improves performance and reduces latency. I hypothesize that there are actually two kinds of latency spikes here. Just taking a wild guess, I wonder if the *remaining* latency spikes are caused by the effect that you mentioned before: namely, the need to write an old CLOG page every time we advance onto a new one. I further speculate that the spikes are more severe on the unpatched code because this effect combines with the one I mentioned before: if there are more simultaneous I/O requests than there are buffers, a new I/O request has to wait for one of the I/Os already in progress to complete. If the new I/O request that has to wait extra-long happens to be the one caused by XID advancement, then things get really ugly. If that hypothesis is correct, then it supports your previous belief that more than one fix is needed here... but it also means we can get a significant and I think quite worthwhile benefit just out of finding a reasonable way to add some more buffers. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
On Thu, Jan 5, 2012 at 4:04 PM, Robert Haas <robertmhaas@gmail.com> wrote: > It appears to me that increasing the number of CLOG buffers reduced > the severity of the latency spikes considerably. In the last 100 > seconds, for example, master has several spikes in the 500-700ms > range, but with 32 CLOG buffers it never goes above 400 ms. Also, the > number of points associated with each spike is considerably less - > each spike seems to affect fewer transactions. So it seems that at > least on this machine, increasing the number of CLOG buffers both > improves performance and reduces latency. I believed before that the increase was worthwhile and now even more so. Let's commit the change to 32. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs <simon@2ndQuadrant.com> wrote: > Robert Haas <robertmhaas@gmail.com> wrote: >> So it seems that at least on this machine, increasing the number >> of CLOG buffers both improves performance and reduces latency. > > I believed before that the increase was worthwhile and now even > more so. > > Let's commit the change to 32. +1 -Kevin
On Thu, Jan 5, 2012 at 4:04 PM, Robert Haas <robertmhaas@gmail.com> wrote: > I hypothesize that there are actually two kinds of latency spikes > here. Just taking a wild guess, I wonder if the *remaining* latency > spikes are caused by the effect that you mentioned before: namely, the > need to write an old CLOG page every time we advance onto a new one. > I further speculate that the spikes are more severe on the unpatched > code because this effect combines with the one I mentioned before: if > there are more simultaneous I/O requests than there are buffers, a new > I/O request has to wait for one of the I/Os already in progress to > complete. If the new I/O request that has to wait extra-long happens > to be the one caused by XID advancement, then things get really ugly. > If that hypothesis is correct, then it supports your previous belief > that more than one fix is needed here... but it also means we can get > a significant and I think quite worthwhile benefit just out of finding > a reasonable way to add some more buffers. Sounds reaonable. Patch to remove clog contention caused by my dirty clog LRU. The patch implements background WAL allocation also, with the intention of being separately tested, if possible. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Thu, Jan 5, 2012 at 11:10 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > Let's commit the change to 32. I would like to do that, but I think we need to at least figure out a way to provide an escape hatch for people without much shared memory. We could do that, perhaps, by using a formula like this: 1 CLOG buffer per 128MB of shared_buffers, with a minimum of 8 and a maximum of 32 I also think it would be a worth a quick test to see how the increase performs on a system with <32 cores. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Jan 5, 2012 at 7:12 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Jan 5, 2012 at 11:10 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >> Let's commit the change to 32. > > I would like to do that, but I think we need to at least figure out a > way to provide an escape hatch for people without much shared memory. > We could do that, perhaps, by using a formula like this: > > 1 CLOG buffer per 128MB of shared_buffers, with a minimum of 8 and a > maximum of 32 We're talking about an extra 192KB or thereabouts and Clog buffers will only be the size of subtrans when we've finished. If you want to have a special low-memory option, then it would need to include many more things than clog buffers. Let's just use a constant value for clog buffers until the low-memory patch arrives. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Jan 5, 2012 at 2:21 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > On Thu, Jan 5, 2012 at 7:12 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Thu, Jan 5, 2012 at 11:10 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >>> Let's commit the change to 32. >> >> I would like to do that, but I think we need to at least figure out a >> way to provide an escape hatch for people without much shared memory. >> We could do that, perhaps, by using a formula like this: >> >> 1 CLOG buffer per 128MB of shared_buffers, with a minimum of 8 and a >> maximum of 32 > > We're talking about an extra 192KB or thereabouts and Clog buffers > will only be the size of subtrans when we've finished. > > If you want to have a special low-memory option, then it would need to > include many more things than clog buffers. > > Let's just use a constant value for clog buffers until the low-memory > patch arrives. Tom already stated that he found that unacceptable. Unless he changes his opinion, we're not going to get far if you're only happy if it's constant and he's only happy if there's a formula. On the other hand, I think there's a decent argument that he should change his opinion, because 192kB of memory is not a lot. However, what I mostly want is something that nobody hates, so we can get it committed and move on. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Jan 5, 2012 at 1:12 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Jan 5, 2012 at 11:10 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >> Let's commit the change to 32. > > I would like to do that, but I think we need to at least figure out a > way to provide an escape hatch for people without much shared memory. > We could do that, perhaps, by using a formula like this: > > 1 CLOG buffer per 128MB of shared_buffers, with a minimum of 8 and a > maximum of 32 The assumption that machines that need this will have gigabytes of shared memory set is not valid IMO. merlin
On Thu, Jan 5, 2012 at 7:26 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Jan 5, 2012 at 2:21 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >> On Thu, Jan 5, 2012 at 7:12 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>> On Thu, Jan 5, 2012 at 11:10 AM, Simon Riggs <simon@2ndquadrant.com> wrote: >>>> Let's commit the change to 32. >>> >>> I would like to do that, but I think we need to at least figure out a >>> way to provide an escape hatch for people without much shared memory. >>> We could do that, perhaps, by using a formula like this: >>> >>> 1 CLOG buffer per 128MB of shared_buffers, with a minimum of 8 and a >>> maximum of 32 >> >> We're talking about an extra 192KB or thereabouts and Clog buffers >> will only be the size of subtrans when we've finished. >> >> If you want to have a special low-memory option, then it would need to >> include many more things than clog buffers. >> >> Let's just use a constant value for clog buffers until the low-memory >> patch arrives. > > Tom already stated that he found that unacceptable. Unless he changes > his opinion, we're not going to get far if you're only happy if it's > constant and he's only happy if there's a formula. > > On the other hand, I think there's a decent argument that he should > change his opinion, because 192kB of memory is not a lot. However, > what I mostly want is something that nobody hates, so we can get it > committed and move on. If that was a reasonable objection it would have applied when we added serializable support, or any other SLRU for that matter. If memory reduction is a concern to anybody, then a separate patch to address *all* issues is required. Blocking this patch makes no sense. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Excerpts from Simon Riggs's message of jue ene 05 16:21:31 -0300 2012: > On Thu, Jan 5, 2012 at 7:12 PM, Robert Haas <robertmhaas@gmail.com> wrote: > > On Thu, Jan 5, 2012 at 11:10 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > >> Let's commit the change to 32. > > > > I would like to do that, but I think we need to at least figure out a > > way to provide an escape hatch for people without much shared memory. > > We could do that, perhaps, by using a formula like this: > > > > 1 CLOG buffer per 128MB of shared_buffers, with a minimum of 8 and a > > maximum of 32 > > We're talking about an extra 192KB or thereabouts and Clog buffers > will only be the size of subtrans when we've finished. Speaking of which, maybe it'd be a good idea to parametrize the subtrans size according to the same (or a similar) formula too. (It might be good to reduce multixact memory consumption too; I'd think that 4+4 pages should be more than sufficient for low memory systems, so making those be half the clog values should be good) So you get both things: reduce memory usage for systems on the low end, which has been slowly increasing lately as we've added more uses of SLRU, and more buffers for large systems. -- Álvaro Herrera <alvherre@commandprompt.com> The PostgreSQL Company - Command Prompt, Inc. PostgreSQL Replication, Consulting, Custom Development, 24x7 support
Robert Haas <robertmhaas@gmail.com> wrote: > Simon Riggs <simon@2ndquadrant.com> wrote: >> Robert Haas <robertmhaas@gmail.com> wrote: >>> Simon Riggs <simon@2ndquadrant.com> wrote: >>>> Let's commit the change to 32. >>> >>> I would like to do that, but I think we need to at least figure >>> out a way to provide an escape hatch for people without much >>> shared memory. We could do that, perhaps, by using a formula >>> like this: >>> >>> 1 CLOG buffer per 128MB of shared_buffers, with a minimum of 8 >>> and a maximum of 32 If we go with such a formula, I think 32 MB would be a more appropriate divisor than 128 MB. Even on very large machines where 32 CLOG buffers would be a clear win, we often can't go above 1 or 2 GB of shared_buffers without hitting latency spikes due to overrun of the RAID controller cache. (Now, that may change if we get DW in, but that's not there yet.) 1 GB / 32 is 32 MB. This would leave CLOG pinned at the minimum of 8 buffers (64 KB) all the way up to shared_buffers of 256 MB. >> Let's just use a constant value for clog buffers until the >> low-memory patch arrives. > Tom already stated that he found that unacceptable. Unless he > changes his opinion, we're not going to get far if you're only > happy if it's constant and he's only happy if there's a formula. > > On the other hand, I think there's a decent argument that he > should change his opinion, because 192kB of memory is not a lot. > However, what I mostly want is something that nobody hates, so we > can get it committed and move on. I wouldn't hate it either way, as long as the divisor isn't too large. -Kevin
Robert Haas <robertmhaas@gmail.com> writes:
> I would like to do that, but I think we need to at least figure out a
> way to provide an escape hatch for people without much shared memory.
> We could do that, perhaps, by using a formula like this:
> 1 CLOG buffer per 128MB of shared_buffers, with a minimum of 8 and a
> maximum of 32
I would be in favor of that, or perhaps some other formula (eg, maybe
the minimum should be less than 8 for when you've got very little shmem).
I think that the reason it's historically been a constant is that the
original coding took advantage of having a compile-time-constant number
of buffers --- but since we went over to the common SLRU infrastructure
for several different logs, there's no longer any benefit whatever to
using a simple constant.
regards, tom lane
Simon Riggs <simon@2ndQuadrant.com> writes:
> On Thu, Jan 5, 2012 at 7:26 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>> On the other hand, I think there's a decent argument that he should
>> change his opinion, because 192kB of memory is not a lot. �However,
>> what I mostly want is something that nobody hates, so we can get it
>> committed and move on.
> If that was a reasonable objection it would have applied when we added
> serializable support, or any other SLRU for that matter.
> If memory reduction is a concern to anybody, then a separate patch to
> address *all* issues is required. Blocking this patch makes no sense.
No, your argument is the one that makes no sense. The fact that things
could be made better for low-mem situations is not an argument for
instead making them worse. Which is what going to a fixed value of 32
would do, in return for no benefit that I can see compared to using a
formula of some sort. The details of the formula barely matter, though
I would like to see one that bottoms out at less than 8 buffers so that
there is some advantage gained for low-memory cases.
regards, tom lane
On Thu, Jan 5, 2012 at 7:57 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I think that the reason it's historically been a constant is that the > original coding took advantage of having a compile-time-constant number > of buffers --- but since we went over to the common SLRU infrastructure > for several different logs, there's no longer any benefit whatever to > using a simple constant. You astound me, you really do. Parameterised slru buffer sizes were proposed about for 8.3 and opposed by you. I guess we all reserve the right to change our minds... -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs <simon@2ndQuadrant.com> writes:
> Parameterised slru buffer sizes were proposed about for 8.3 and opposed by you.
> I guess we all reserve the right to change our minds...
When presented with new data, sure. Robert's results offer a reason to
worry about this, which we did not have before now.
regards, tom lane
On Thu, Jan 5, 2012 at 2:44 PM, Kevin Grittner <Kevin.Grittner@wicourts.gov> wrote: > If we go with such a formula, I think 32 MB would be a more > appropriate divisor than 128 MB. Even on very large machines where > 32 CLOG buffers would be a clear win, we often can't go above 1 or 2 > GB of shared_buffers without hitting latency spikes due to overrun > of the RAID controller cache. (Now, that may change if we get DW > in, but that's not there yet.) 1 GB / 32 is 32 MB. This would > leave CLOG pinned at the minimum of 8 buffers (64 KB) all the way up > to shared_buffers of 256 MB. That seems reasonable to me. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Jan 5, 2012 at 2:57 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I would be in favor of that, or perhaps some other formula (eg, maybe > the minimum should be less than 8 for when you've got very little shmem). I have some results that show that, under the right set of circumstances, 8->32 is a win, and I can quantify by how much it wins.I don't have any data at all to quantify the cost ofdropping the minimum from 8->6, or from 8->4, and therefore I'm reluctant to do it.My guess is that it's a bad idea, anyway. Even ona system where shared_buffers is just 8MB, we have 1024 regular buffers and 8 CLOG buffers. If we reduce the number of CLOG buffers from 8 to 4 (i.e. by 50%), we can increase the number of regular buffers from 1024 to 1028 (i.e. by <0.5%). Maybe you can find a case where that comes out to a win, but you might have to look pretty hard. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Jan 5, 2012 at 2:25 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Jan 5, 2012 at 2:44 PM, Kevin Grittner > <Kevin.Grittner@wicourts.gov> wrote: >> If we go with such a formula, I think 32 MB would be a more >> appropriate divisor than 128 MB. Even on very large machines where >> 32 CLOG buffers would be a clear win, we often can't go above 1 or 2 >> GB of shared_buffers without hitting latency spikes due to overrun >> of the RAID controller cache. (Now, that may change if we get DW >> in, but that's not there yet.) 1 GB / 32 is 32 MB. This would >> leave CLOG pinned at the minimum of 8 buffers (64 KB) all the way up >> to shared_buffers of 256 MB. > > That seems reasonable to me. likewise (champion bikeshedder here). It just so happens I typically set 'large' server shared memory to 256mb. merlin
Robert Haas <robertmhaas@gmail.com> writes:
> On Thu, Jan 5, 2012 at 2:57 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> I would be in favor of that, or perhaps some other formula (eg, maybe
>> the minimum should be less than 8 for when you've got very little shmem).
> I have some results that show that, under the right set of
> circumstances, 8->32 is a win, and I can quantify by how much it wins.
> I don't have any data at all to quantify the cost of dropping the
> minimum from 8->6, or from 8->4, and therefore I'm reluctant to do it.
> My guess is that it's a bad idea, anyway. Even on a system where
> shared_buffers is just 8MB, we have 1024 regular buffers and 8 CLOG
> buffers. If we reduce the number of CLOG buffers from 8 to 4 (i.e. by
> 50%), we can increase the number of regular buffers from 1024 to 1028
> (i.e. by <0.5%). Maybe you can find a case where that comes out to a
> win, but you might have to look pretty hard.
I think you're rejecting the concept too easily. A setup with very
little shmem is only going to be suitable for low-velocity systems that
are not pushing too many transactions through per second, so it's not
likely to need so many CLOG buffers. And frankly I'm not that concerned
about what the performance is like: I'm more concerned about whether
PG will start up at all without modifying the system shmem limits,
on systems with legacy values for SHMMAX etc. Shaving a few
single-purpose buffers to make back what we spent on SSI, for example,
seems like a good idea to me.
regards, tom lane
On Thu, Jan 5, 2012 at 10:34 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Thu, Jan 5, 2012 at 2:57 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> I would be in favor of that, or perhaps some other formula (eg, maybe >>> the minimum should be less than 8 for when you've got very little shmem). > >> I have some results that show that, under the right set of >> circumstances, 8->32 is a win, and I can quantify by how much it wins. >> I don't have any data at all to quantify the cost of dropping the >> minimum from 8->6, or from 8->4, and therefore I'm reluctant to do it. >> My guess is that it's a bad idea, anyway. Even on a system where >> shared_buffers is just 8MB, we have 1024 regular buffers and 8 CLOG >> buffers. If we reduce the number of CLOG buffers from 8 to 4 (i.e. by >> 50%), we can increase the number of regular buffers from 1024 to 1028 >> (i.e. by <0.5%). Maybe you can find a case where that comes out to a >> win, but you might have to look pretty hard. > > I think you're rejecting the concept too easily. A setup with very > little shmem is only going to be suitable for low-velocity systems that > are not pushing too many transactions through per second, so it's not > likely to need so many CLOG buffers. And frankly I'm not that concerned > about what the performance is like: I'm more concerned about whether > PG will start up at all without modifying the system shmem limits, > on systems with legacy values for SHMMAX etc. Shaving a few > single-purpose buffers to make back what we spent on SSI, for example, > seems like a good idea to me. Having 32 clog buffers is important at the high end. I don't think that other complexities should mask that truth and lead to us not doing anything on this topic for this release. Please can we either make it user configurable? prepared transactions require config, lock table size is configurable also, so having SSI and clog require config is not too much of a stretch. We can then discuss intelligent autotuning behaviour when we have more time and more evidence. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Thu, Jan 5, 2012 at 5:34 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> On Thu, Jan 5, 2012 at 2:57 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> I would be in favor of that, or perhaps some other formula (eg, maybe >>> the minimum should be less than 8 for when you've got very little shmem). > >> I have some results that show that, under the right set of >> circumstances, 8->32 is a win, and I can quantify by how much it wins. >> I don't have any data at all to quantify the cost of dropping the >> minimum from 8->6, or from 8->4, and therefore I'm reluctant to do it. >> My guess is that it's a bad idea, anyway. Even on a system where >> shared_buffers is just 8MB, we have 1024 regular buffers and 8 CLOG >> buffers. If we reduce the number of CLOG buffers from 8 to 4 (i.e. by >> 50%), we can increase the number of regular buffers from 1024 to 1028 >> (i.e. by <0.5%). Maybe you can find a case where that comes out to a >> win, but you might have to look pretty hard. > > I think you're rejecting the concept too easily. A setup with very > little shmem is only going to be suitable for low-velocity systems that > are not pushing too many transactions through per second, so it's not > likely to need so many CLOG buffers. Well, if you take the same workload and spread it out over a long period of time, it will still have just as many CLOG misses or shared_buffers misses as it had when you did it all at top speed. Admittedly, you're unlikely to run into the situation where you have people wanting to do simultaneous CLOG reads than there are buffers, but you'll still thrash the cache. > And frankly I'm not that concerned > about what the performance is like: I'm more concerned about whether > PG will start up at all without modifying the system shmem limits, > on systems with legacy values for SHMMAX etc. After thinking about this a bit, I think the problem is that the divisor we picked is still too high. Suppose we set num_clog_buffers = (shared_buffers / 4MB), with a minimum of 4 and maximum of 32. That way, pretty much anyone who bothers to set shared_buffers to a non-default value will get 32 CLOG buffers, which should be fine, but people who are in the 32MB-or-less range can ramp down lower than what we've allowed in the past. That seems like it might give us the best of both worlds. > Shaving a few > single-purpose buffers to make back what we spent on SSI, for example, > seems like a good idea to me. I think if we want to buy back that memory, the best way to do it would be to add a GUC to disable SSI at startup time. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Simon Riggs <simon@2ndQuadrant.com> writes:
> Please can we either make it user configurable?
Weren't you just complaining that *I* was overcomplicating things?
I see no evidence to justify inventing a user-visible GUC here.
We have rough consensus on both the need for and the shape of a formula,
with just minor discussion about the exact parameters to plug into it.
Punting the problem off to a GUC is not a better answer.
regards, tom lane
Robert Haas <robertmhaas@gmail.com> writes:
> After thinking about this a bit, I think the problem is that the
> divisor we picked is still too high. Suppose we set num_clog_buffers
> = (shared_buffers / 4MB), with a minimum of 4 and maximum of 32.
Works for me.
regards, tom lane
On Fri, Jan 6, 2012 at 3:55 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Simon Riggs <simon@2ndQuadrant.com> writes: >> Please can we either make it user configurable? > > Weren't you just complaining that *I* was overcomplicating things? > I see no evidence to justify inventing a user-visible GUC here. > We have rough consensus on both the need for and the shape of a formula, > with just minor discussion about the exact parameters to plug into it. > Punting the problem off to a GUC is not a better answer. As long as we get 32 buffers on big systems, I have no complaint. I'm sorry if I moaned at you personally. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Jan 6, 2012 at 11:05 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> After thinking about this a bit, I think the problem is that the >> divisor we picked is still too high. Suppose we set num_clog_buffers >> = (shared_buffers / 4MB), with a minimum of 4 and maximum of 32. > > Works for me. Done. I tested this on my MacBook Pro and I see no statistically significant difference from the change on a couple of small pgbench tests. Hopefully that means this is good on large boxes and at worst harmless on small ones. As far as I can see, the trade-off is this: If you increase the number of CLOG buffers, then your CLOG miss rate will go down. On the other hand, the cost of looking up a CLOG buffer will go up. At some point, the reduction in the miss rate will not be enough to pay for a longer linear search - which also means holding CLogControlLock. I think it'd probably be worthwhile to think about looking for something slightly smarter than a linear search at some point, and maybe also looking for a way to partition the locking better. But, this at least picks the available load-hanging fruit, which is a good place to start. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Jan 5, 2012 at 6:26 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > Patch to remove clog contention caused by dirty clog LRU. v2, minor changes, updated for recent commits -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Attachment
On Thu, Jan 12, 2012 at 4:49 AM, Simon Riggs <simon@2ndquadrant.com> wrote: > On Thu, Jan 5, 2012 at 6:26 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > >> Patch to remove clog contention caused by dirty clog LRU. > > v2, minor changes, updated for recent commits This no longer applies to file src/backend/postmaster/bgwriter.c, due to the latch code, and I'm not confident I know how to fix it. Cheers, Jeff