Thread: high io BUT huge amount of free memory
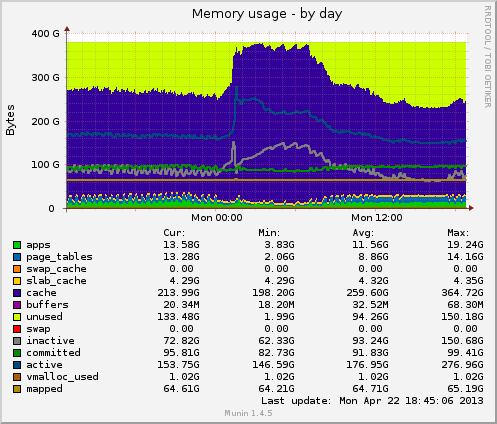
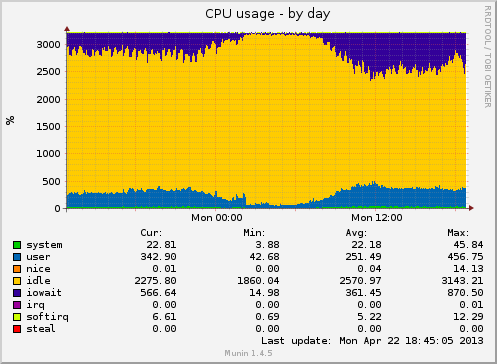
My first message has been banned for too many latters. > Hi all There is something wrong and ugly. 1) Intel 32 core = 2*8 *2threads Linux avi-sql09 2.6.32-5-amd64 #1 SMP Sun May 6 04:00:17 UTC 2012 x86_64 GNU/Linux PostgreSQL 9.2.2 on x86_64-unknown-linux-gnu, compiled by gcc-4.4.real (Debian 4.4.5-8) 4.4.5, 64-bit shared_buffers 64GB / constant hit rate - 99,18 max_connections 160 / with pgbouncer pools there could not be more than 120 connections at all work_mem 32M checkpoint 1h 1.0 swap off numa off, interleaving on 24*128GB HDD (RAID10) with 2GB bbu (1,5w+0,5r) 2) free -g total used free shared buffers cached Mem: 378 250 128 0 0 229 -/+ buffers/cache: 20 357 and ! disks usage 100% (free 128GB! WHY?) disk throughput - up-to 30MB/s (24r+6w) io - up-to 2,5-3K/s (0,5w + 2-2,5r) 3) so maybe I've got something like this http://www.databasesoup.com/2012/04/red-hat-kernel-cache-clearing-issue.html or this http://comments.gmane.org/gmane.comp.db.sqlite.general/79457 4) now i think a) upgrade linux core or b) set buffers to something like 300-320Gb my warm work set is about 300-400GB db at all - 700GB typical work load - pk-index-scans -- looking forward thanks > Mikhail
Attachment
{kind=link}
{kind=link}
On Mon, Apr 22, 2013 at 1:22 PM, Миша Тюрин <tmihail@bk.ru> wrote: > > My first message has been banned for too many latters. > >> > Hi all > There is something wrong and ugly. > > 1) > Intel 32 core = 2*8 *2threads > > Linux avi-sql09 2.6.32-5-amd64 #1 SMP Sun May 6 04:00:17 UTC 2012 x86_64 GNU/Linux > > PostgreSQL 9.2.2 on x86_64-unknown-linux-gnu, compiled by gcc-4.4.real (Debian 4.4.5-8) 4.4.5, 64-bit > shared_buffers 64GB / constant hit rate - 99,18 > max_connections 160 / with pgbouncer pools there could not be more than 120 connections at all > work_mem 32M > checkpoint 1h 1.0 > swap off > numa off, interleaving on > > 24*128GB HDD (RAID10) with 2GB bbu (1,5w+0,5r) > > 2) > free -g > total used free shared buffers cached > Mem: 378 250 128 0 0 229 > -/+ buffers/cache: 20 357 > > and > ! disks usage 100% (free 128GB! WHY?) > > disk throughput - up-to 30MB/s (24r+6w) > io - up-to 2,5-3K/s (0,5w + 2-2,5r) > > 3) so maybe I've got something like this > http://www.databasesoup.com/2012/04/red-hat-kernel-cache-clearing-issue.html > or this > http://comments.gmane.org/gmane.comp.db.sqlite.general/79457 > > 4) now i think > a) upgrade linux core or > b) set buffers to something like 300-320Gb > my warm work set is about 300-400GB > db at all - 700GB > > typical work load - pk-index-scans > > -- > looking forward > thanks this topic is more suitable for -performance. check out this: http://frosty-postgres.blogspot.com/2012/08/postgresql-numa-and-zone-reclaim-mode.html merlin
On Mon, Apr 22, 2013 at 11:22 AM, Миша Тюрин <tmihail@bk.ru> wrote: > free -g > total used free shared buffers cached > Mem: 378 250 128 0 0 229 > -/+ buffers/cache: 20 357 > > and > ! disks usage 100% (free 128GB! WHY?) > > disk throughput - up-to 30MB/s (24r+6w) > io - up-to 2,5-3K/s (0,5w + 2-2,5r) What do iostat -xk 10 and vmstat -SM 10 show? > > 3) so maybe I've got something like this > http://www.databasesoup.com/2012/04/red-hat-kernel-cache-clearing-issue.html > or this > http://comments.gmane.org/gmane.comp.db.sqlite.general/79457 > > 4) now i think > a) upgrade linux core or > b) set buffers to something like 300-320Gb > my warm work set is about 300-400GB > db at all - 700GB > > typical work load - pk-index-scans > > -- > looking forward > thanks >> > Mikhail > > > -- > Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-hackers > -- Kind regards, Sergey Konoplev Database and Software Consultant Profile: http://www.linkedin.com/in/grayhemp Phone: USA +1 (415) 867-9984, Russia +7 (901) 903-0499, +7 (988) 888-1979 Skype: gray-hemp Jabber: gray.ru@gmail.com
On 04/22/2013 05:12 PM, Merlin Moncure wrote: >> free -g >> total used free shared buffers cached >> Mem: 378 250 128 0 0 229 >> -/+ buffers/cache: 20 357 This is most likely a NUMA issue. There really seems to be some kind of horrible flaw in the Linux kernel when it comes to properly handling NUMA on large memory systems. What does this say: numactl --hardware -- Shaun Thomas OptionsHouse | 141 W. Jackson Blvd. | Suite 500 | Chicago IL, 60604 312-676-8870 sthomas@optionshouse.com ______________________________________________ See http://www.peak6.com/email_disclaimer/ for terms and conditions related to this email
On Tue, Apr 23, 2013 at 10:50 AM, Shaun Thomas <sthomas@optionshouse.com> wrote: > This is most likely a NUMA issue. There really seems to be some kind of > horrible flaw in the Linux kernel when it comes to properly handling NUMA on > large memory systems. Are you referring to the fact that vm.zone_reclaim_mode = 1 is an idiotic default? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 04/24/2013 08:24 AM, Robert Haas wrote: > Are you referring to the fact that vm.zone_reclaim_mode = 1 is an > idiotic default? Well... it is. But even on systems where it's not the default or is explicitly disabled, there's just something hideously wrong with NUMA in general. Take a look at our numa distribution on a heavily loaded system: available: 2 nodes (0-1) node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 node 0 size: 36853 MB node 0 free: 14315 MB node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 node 1 size: 36863 MB node 1 free: 300 MB node distances: node 0 1 0: 10 20 1: 20 10 What the hell? Seriously? Using numactl and starting in interleave didn't fix this, either. It just... arbitrarily ignores a huge chunk of memory for no discernible reason. The memory pressure code in Linux is extremely fucked up. I can't find it right now, but the memory management algorithm makes some pretty ridiculous assumptions once you pass half memory usage, regarding what is in active and inactive cache. I hate to rant, but it gets clearer to me every day that Linux is optimized for desktop systems, and generally only kinda works for servers. Once you start throwing vast amounts of memory, CPU, and processes at it though, things start to get unpredictable. That all goes back to my earlier threads that disabling process autogrouping via the kernel.sched_autogroup_enabled setting, magically gave us 20-30% better performance. The optimal setting for a server is clearly to disable process autogrouping, and yet it's enabled by default, and strongly advocated by Linus himself as a vast improvement. I get it. It's better for desktop systems. But the LAMP stack alone has probably a couple orders of magnitude more use cases than Joe Blow's Pentium 4 in his basement. Yet it's the latter case that's optimized for. Servers are getting shafted in a lot of cases, and it's actually starting to make me angry. -- Shaun Thomas OptionsHouse | 141 W. Jackson Blvd. | Suite 500 | Chicago IL, 60604 312-676-8870 sthomas@optionshouse.com ______________________________________________ See http://www.peak6.com/email_disclaimer/ for terms and conditions related to this email
On 2013-04-24 08:39:09 -0500, Shaun Thomas wrote: > The memory pressure code in Linux is extremely fucked up. I can't find it > right now, but the memory management algorithm makes some pretty ridiculous > assumptions once you pass half memory usage, regarding what is in active and > inactive cache. > > I hate to rant, but it gets clearer to me every day that Linux is optimized > for desktop systems, and generally only kinda works for servers. Once you > start throwing vast amounts of memory, CPU, and processes at it though, > things start to get unpredictable. > That all goes back to my earlier threads that disabling process autogrouping > via the kernel.sched_autogroup_enabled setting, magically gave us 20-30% > better performance. The optimal setting for a server is clearly to disable > process autogrouping, and yet it's enabled by default, and strongly > advocated by Linus himself as a vast improvement. > I get it. It's better for desktop systems. But the LAMP stack alone has > probably a couple orders of magnitude more use cases than Joe Blow's Pentium > 4 in his basement. Yet it's the latter case that's optimized for. IIRC there have been some scalability improvements to that code. > Servers are getting shafted in a lot of cases, and it's actually starting to > make me angry. Uh. Ranting can be rather healthy thing every now and then and it good for the soul and such. But. Did you actually try reporting those issues? In my experience the mm and scheduler folks are rather helpful if they see you're actually interested in fixing a problem. I have seen rants about this topic on various pg lists for the last months but I can't remember seeing mails on lkml about it. How should they fix what they don't know about? You know, before Robert got access to the bigger machine we *also* had some very bad behaviour on them. And our writeout mechanism/buffer acquisition mechanism still utterly sucks there. But that doesn't mean we don't care. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 04/24/2013 08:49 AM, Andres Freund wrote: > Uh. Ranting can be rather healthy thing every now and then and it good > for the soul and such. But. Did you actually try reporting those issues? That's actually part of the problem. How do you report: Throwing a lot of processes at a high-memory system seems to break the mm code in horrible ways. I'm asking seriously here, because I have no clue how to isolate this behavior. It's clearly happening often enough that random people are starting to notice now that bigger servers are becoming the norm. I'm also not a kernel dev in any sense of the word. My C is so rusty, I can barely even read the patches going through the ML. I feel comfortable posting to PG lists because that's my bread and butter. Kernel lists seem way more imposing, and I'm probably not the only one who feels that way. I guess I don't mean to imply that kernel devs don't care. Maybe the right way to put it is that there don't seem to be enough kernel devs being provided with more capable testing hardware. Which is odd, considering Red Hat's involvement and activity on the kernel. I apologize, though. These last few months have been really frustrating thanks to this and other odd kernel-related issues. We've reached an equilibrium where the occasional waste of 20GB of RAM doesn't completely cripple the system, but this thread kinda struck a sore point. :) -- Shaun Thomas OptionsHouse | 141 W. Jackson Blvd. | Suite 500 | Chicago IL, 60604 312-676-8870 sthomas@optionshouse.com ______________________________________________ See http://www.peak6.com/email_disclaimer/ for terms and conditions related to this email
On 2013-04-24 09:06:39 -0500, Shaun Thomas wrote: > On 04/24/2013 08:49 AM, Andres Freund wrote: > > >Uh. Ranting can be rather healthy thing every now and then and it good > >for the soul and such. But. Did you actually try reporting those issues? > > That's actually part of the problem. How do you report: > > Throwing a lot of processes at a high-memory system seems to break the mm > code in horrible ways. Well. Report memory distribution. Report perf profiles. Ask *them* what information they need. They aren't grumpy if you are behaving sensibly. YMMV of course. > I'm asking seriously here, because I have no clue how to isolate this > behavior. It's clearly happening often enough that random people are > starting to notice now that bigger servers are becoming the norm. > > I'm also not a kernel dev in any sense of the word. My C is so rusty, I can > barely even read the patches going through the ML. I feel comfortable > posting to PG lists because that's my bread and butter. Kernel lists seem > way more imposing, and I'm probably not the only one who feels that way. I can understand that. But you had to jump over the fence to post here once as well ;). Really, report it and see what comes out. The worst that can happen is that you get a grumpy email ;) And in the end, jumping might ease the pain in the long run considerably even if its uncomfortable at first... Feel free to CC me. > I guess I don't mean to imply that kernel devs don't care. Maybe the right > way to put it is that there don't seem to be enough kernel devs being > provided with more capable testing hardware. Which is odd, considering Red > Hat's involvement and activity on the kernel. There are quite some people using huge servers, but that doesn't imply they are seing the same problems. During testing they mostly use a set of a few benchmarks (part of which is pgbench btw) and apparently they don't show this problem. Also this is horribly workload and hardware dependent. There are enough people happily using postgres on linux on far bigger hardware than what you reported upthread. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
thanks a lot for responses 1) just remind my case Intel 32 core = 2*8 *2threads Linux 2.6.32-5-amd64 #1 SMP Sun May 6 04:00:17 UTC 2012 x86_64 GNU/Linux PostgreSQL 9.2.2 on x86_64-unknown-linux-gnu, compiled by gcc-4.4.real (Debian 4.4.5-8) 4.4.5, 64-bit shared_buffers 64GB / constant hit rate - 99,18 max_connections 160 / with pgbouncer pools there could not be more than 120 connections at all work_mem 32M checkpoint 1h 1.0 swap off numa off, interleaving on and ! disks usage 100% (free 128GB! WHY?) disk throughput - up-to 30MB/s (24r+6w) io - up-to 2,5-3K/s (0,5w + 2-2,5r) typical work load - pk-index-scans my warm work set is about 400GB db at all - 700GB 2) numactl mtyurin@avi-sql09:~$ numactl --hardware available: 1 nodes (0-0) node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 node 0 size: 393181 MB node 0 free: 146029 MB node distances: node 0 0: 10 3) !! i just found suspicious relation between "active" processes and free memory. ~1GB per process. in 376GB total memmory and 32 core if ( user cpu + io wait ) is ~140% then i have ~140GB free. but it could be just a coincidence. 4) now i think a) upgrade linux core (to 3.2!?) and then (if case still will be) b) set buffers to something like 300-320Gb 5) what do you know about workload in Berkus's case http://www.databasesoup.com/2012/04/red-hat-kernel-cache-clearing-issue.html?
typo > if ( user cpu + io wait ) is ~140% then i have ~140GB free. 140% ===>> 1400% if ~14 cores are busy then ~140GB is free 10GB per process hmmm...
vm state root@avi-sql09:~# /sbin/sysctl -a|grep vm vm.overcommit_memory = 0 vm.panic_on_oom = 0 vm.oom_kill_allocating_task = 0 vm.oom_dump_tasks = 0 vm.overcommit_ratio = 50 vm.page-cluster = 3 vm.dirty_background_ratio = 10 vm.dirty_background_bytes = 0 vm.dirty_ratio = 20 vm.dirty_bytes = 0 vm.dirty_writeback_centisecs = 500 vm.dirty_expire_centisecs = 3000 vm.nr_pdflush_threads = 0 vm.swappiness = 0 vm.nr_hugepages = 0 vm.hugetlb_shm_group = 0 vm.hugepages_treat_as_movable = 0 vm.nr_overcommit_hugepages = 0 vm.lowmem_reserve_ratio = 256 256 32 vm.drop_caches = 0 vm.min_free_kbytes = 65536 vm.percpu_pagelist_fraction = 0 vm.max_map_count = 65530 vm.laptop_mode = 0 vm.block_dump = 0 vm.vfs_cache_pressure = 100 vm.legacy_va_layout = 0 vm.zone_reclaim_mode = 0 vm.min_unmapped_ratio = 1 vm.min_slab_ratio = 5 vm.stat_interval = 1 vm.mmap_min_addr = 65536 vm.numa_zonelist_order = default vm.scan_unevictable_pages = 0 vm.memory_failure_early_kill = 0 vm.memory_failure_recovery = 1
On 04/24/2013 09:39 PM, Shaun Thomas wrote: > On 04/24/2013 08:24 AM, Robert Haas wrote: > >> Are you referring to the fact that vm.zone_reclaim_mode = 1 is an >> idiotic default? > Servers are getting shafted in a lot of cases, and it's actually > starting to make me angry. > A significant part of that problem is that desktop users and people developing for desktops *test* kernels before or shortly after their release. Most server operators won't let a new kernel anywhere near their machines, so reports of problems on big real-world servers lag severely behind Linux kernel development. By the time last years' issues are fixed, there's a whole new crop of issues that make the new kernel problematic in other ways. There *are* teams testing new kernels on big hardware, but this takes money and resources not everyone has. They're also limited in what tests the have available to them. One of the big things that you can do to help is *produce automated test cases* that demonstrate performance problems so they can be incorporated into future kernel testing and benchmarking processes. You can also help test newer kernels to see if your issues are fixed. I know full well how frustrating it can be when you feel your use cases and problems are ignored or dismissed (I've worked on Java EE) ... but the only way I've ever found to get genuine progress is to put that aside and help. -- Craig Ringer http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Apr 24, 2013 at 08:39:09AM -0500, Shaun Thomas wrote: > On 04/24/2013 08:24 AM, Robert Haas wrote: > > >Are you referring to the fact that vm.zone_reclaim_mode = 1 is an > >idiotic default? > > Well... it is. But even on systems where it's not the default or is > explicitly disabled, there's just something hideously wrong with > NUMA in general. Take a look at our numa distribution on a heavily > loaded system: > > available: 2 nodes (0-1) > node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 > node 0 size: 36853 MB > node 0 free: 14315 MB > node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 > node 1 size: 36863 MB > node 1 free: 300 MB > node distances: > node 0 1 > 0: 10 20 > 1: 20 10 > > What the hell? Seriously? Using numactl and starting in interleave > didn't fix this, either. It just... arbitrarily ignores a huge chunk > of memory for no discernible reason. Sorry to be dense here, but what is the problem with that output? That there is a lot of memory marked as "free"? Why would it mark any memory free? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + It's impossible for everything to be true. +
On 05/01/2013 06:37 PM, Bruce Momjian wrote: > Sorry to be dense here, but what is the problem with that output? > That there is a lot of memory marked as "free"? Why would it mark > any memory free? That's kind of my point. :) That 14GB isn't allocated to cache, buffers, any process, or anything else. It's just... free. In the middle of the day, where 800 PG threads are pulling 7000TPS on average. Based on that scenario, I'd like to think it would cache pretty aggressively, but instead, it's just leaving 14GB around to do absolutely nothing. It makes me sad. :( -- Shaun Thomas OptionsHouse | 141 W. Jackson Blvd. | Suite 500 | Chicago IL, 60604 312-676-8870 sthomas@optionshouse.com ______________________________________________ See http://www.peak6.com/email_disclaimer/ for terms and conditions related to this email
> That's kind of my point. :) That 14GB isn't allocated to cache, buffers, > any process, or anything else. It's just... free. In the middle of the > day, where 800 PG threads are pulling 7000TPS on average. Based on that > scenario, I'd like to think it would cache pretty aggressively, but > instead, it's just leaving 14GB around to do absolutely nothing. > > It makes me sad. :( Yeah, this is why I want to go to Linux Plumbers this year. The Kernel.org engineers are increasingly doing things which makes Linux unsuitable for applications which depend on the filesystem. There is a good, but sad, reason for this: IBM and Oracle and their partners are the largest employers of people hacking on core Linux memory/IO functionality, and both of those companies use DirectIO extensively in their products. -- Josh Berkus PostgreSQL Experts Inc. http://pgexperts.com
On 05/02/2013 12:04 PM, Josh Berkus wrote: > There is a good, but sad, reason for this: IBM and Oracle and their > partners are the largest employers of people hacking on core Linux > memory/IO functionality, and both of those companies use DirectIO > extensively in their products. I never thought of that. Somehow I figured all the Redhat engineers would somehow counterbalance that kind of influence. But that brings up an interesting question. How hard / feasible would it be to add DIO functionality to PG itself? I've already heard chatter (Robert Haas?) about converting the shared memory allocation to an anonymous block, so could we simultaneously open up a DMA relationship? -- Shaun Thomas OptionsHouse | 141 W. Jackson Blvd. | Suite 500 | Chicago IL, 60604 312-676-8870 sthomas@optionshouse.com ______________________________________________ See http://www.peak6.com/email_disclaimer/ for terms and conditions related to this email
On 2013-05-02 16:13:42 -0500, Shaun Thomas wrote: > On 05/02/2013 12:04 PM, Josh Berkus wrote: > Yeah, this is why I want to go to Linux Plumbers this year. The > Kernel.org engineers are increasingly doing things which makes Linux > unsuitable for applications which depend on the filesystem. Uh. Yea. > >There is a good, but sad, reason for this: IBM and Oracle and their > >partners are the largest employers of people hacking on core Linux > >memory/IO functionality, and both of those companies use DirectIO > >extensively in their products. > > I never thought of that. Somehow I figured all the Redhat engineers would > somehow counterbalance that kind of influence. I think the reason you never thought of that is that it doesn't have much to do with reality. Calling the linux direct io implemention well maintained and well performing is a rather bad joke. Sorry, I can't find a friendlier description. And no, thats not my opinion. That's the opinion of the people maintaining it. Google it if you don't believe me. Also, IBM and Oracle - which afaik was never really up there - haven't been at top of the contributing companies list for a while. Like several years. I can only repeat myself: The blame game against the linux kernel played here on the lists is neither an accurate description of reality nor helpful. The only two recent occasions where I can remember postgres people reaching out to lkml the reported problems got fixed in an reasonable amount of time. One was the lseek(2) scalability issue discovered by Robert which, after some prodding by yours truly, got solved entirely by Andi Kleen and some major performance regression in an development (!) kernel that was made visible by pg that got fixed before the final release was made. Note well that they *do* regularly test development kernels with various version of postgres. We don't do the reverse in any way that is remotely systematic. Report the problems you find instead of whining! And remember when you measure the performance of a several year old kernel how we react when somebody complains too loudly about performance problems in 8.3. Yes it sucks majorly to update your kernel. But quite often its far easier than updating the postgres major version. And way easier to roll back. > But that brings up an interesting question. How hard / feasible would it be > to add DIO functionality to PG itself? I don't think there is too much chance of that - but I also don't really see the point in trying to do it. We should start by improving postgres buffer writeout which isn't that great, especially with big shared buffers. We would have to invest quite a lot of work in how our buffering and writeout works to make DIO perform nicely. > I've already heard chatter (Robert > Haas?) about converting the shared memory allocation to an anonymous block, > so could we simultaneously open up a DMA relationship? We've got that in 9.3 which is absolutely fabulous! But that's not related to doing DMA which you cannot (and should not!) do from userspace. I hate to be so harsh, but this topic has been getting on my nerves for quite a while now and its constantly getting worse. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Fri, May 3, 2013 at 12:09 AM, Andres Freund <andres@2ndquadrant.com> wrote: >> But that brings up an interesting question. How hard / feasible would it be >> to add DIO functionality to PG itself? > > I don't think there is too much chance of that - but I also don't really > see the point in trying to do it. We should start by improving postgres > buffer writeout which isn't that great, especially with big shared > buffers. We would have to invest quite a lot of work in how our > buffering and writeout works to make DIO perform nicely. I think eventually we'll probably go that route. Double-buffering is just too expensive not to solve one way or the other. The other is using mmap and somehow solving the WAL ordering issue which would be nice but seems even less likely to succeed. The problem with DIO which has been covered many times in the past here is that then we need to learn a lot about the hardware. It would be up to us to schedule i/o efficiently for the hardware layout which is not an easy problem especially if we're not always the only consumer of that hardware bandwidth. I don't think it's worth going through the discussions again unless someone is actually interested in writing the code and has new ideas on how to solve these problems. -- greg
On 05/03/2013 07:09 AM, Andres Freund wrote: > We've got that in 9.3 which is absolutely fabulous! But that's not > related to doing DMA which you cannot (and should not!) do from > userspace. You can do zero-copy DMA directly into userspace buffers. It requires root (or suitable capabilities that land up equivalent to root anyway) and requires driver support, and it's often a terrible idea, but it's possible. It's used by a lot of embedded systems, by infiniband, and (if I vaguely recall correctly) by things like video4linux drivers. You can use get_user_pages and set the write flag. Linux Device Drivers chapter 15 discusses it. That said, I think some of the earlier parts of this discussion confused direct asynchronous I/O with DMA. Within-kernel DMA may be (ok, is) used to implement DIO, but that doesn't mean you're DMA'ing directly into userspace buffers. -- Craig Ringer http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Hi all hackers again! Since i had got this topic there many test was done by our team and many papers was seen. And then I noticed that os_page_replacement_algorithmwith CLOCK and others features might * interfere / overlap * with/on postgres_shared_buffers. I also think there are positive correlation between the write load and the pressure on file cache in case with large sharedbuffers. I assumed if i would set smaller size of buffers that cache could work more effective because files pages has more probabilityto be placed in the right place in memory. After all we set shared buffers down to 16GB ( instead of 64GB ) and we got new pictures. Now we have alive raid! 16GB sharedbuffers => and we won 80 GB of server memory! It is good result. But upto 70GB of memory are still unused // insteadof 150. In future I think we can set shared buffers more close to zero or to 100% of all available memory. Many thanks Oleg Bartunov and Fedor Sigaev for their tests and some interesting assumptions. -- Mikhail >Hi all >There is something wrong and ugly. > >1) >Intel 32 core = 2*8 *2threads > >Linux avi-sql09 2.6.32-5-amd64 #1 SMP Sun May 6 04:00:17 UTC 2012 x86_64 GNU/Linux > >PostgreSQL 9.2.2 on x86_64-unknown-linux-gnu, compiled by gcc-4.4.real (Debian 4.4.5-8) 4.4.5, 64-bit >shared_buffers 64GB / constant hit rate - 99,18 >max_connections 160 / with pgbouncer pools there could not be more than 120 connections at all >work_mem 32M >checkpoint 1h 1.0 >swap off >numa off, interleaving on > >24*128GB HDD (RAID10) with 2GB bbu (1,5w+0,5r) > >2) >free -g > total used free shared buffers cached >Mem: 378 250 128 0 0 229 >-/+ buffers/cache: 20 357 > >and >! disks usage 100% (free 128GB! WHY?) > >disk throughput - up-to 30MB/s (24r+6w) >io - up-to 2,5-3K/s (0,5w + 2-2,5r) > > >typical work load - pk-index-scans >
Attachment
{kind=link}
{kind=link}
{kind=link}
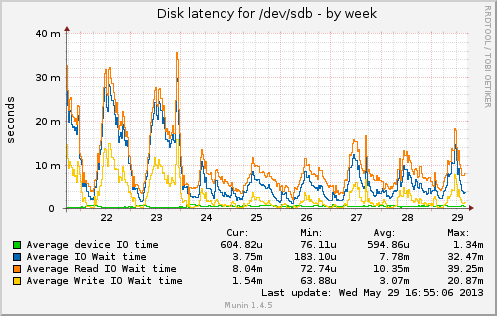{kind=link}
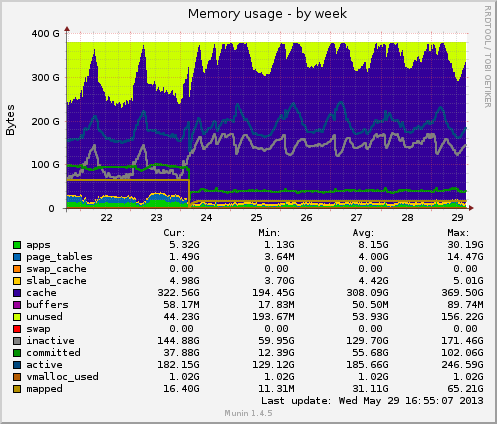{kind=link}
On Mon, Jun 3, 2013 at 11:08 AM, Миша Тюрин <tmihail@bk.ru> wrote: > Hi all hackers again! > Since i had got this topic there many test was done by our team and many papers was seen. And then I noticed that os_page_replacement_algorithmwith CLOCK and others features > > might * interfere / overlap * with/on postgres_shared_buffers. > > I also think there are positive correlation between the write load and the pressure on file cache in case with large sharedbuffers. > > I assumed if i would set smaller size of buffers that cache could work more effective because files pages has more probabilityto be placed in the right place in memory. > > After all we set shared buffers down to 16GB ( instead of 64GB ) and we got new pictures. Now we have alive raid! 16GBshared buffers => and we won 80 GB of server memory! It is good result. But upto 70GB of memory are still unused // insteadof 150. In future I think we can set shared buffers more close to zero or to 100% of all available memory. > > Many thanks Oleg Bartunov and Fedor Sigaev for their tests and some interesting assumptions. hm, in that case, wouldn't adding 48gb of physical memory have approximately the same effect? or is something else going on? merlin
> hm, in that case, wouldn't adding 48gb of physical memory have > approximately the same effect? or is something else going on? imho, adding 48gb would have no effects. server already has 376GB memory and still has a lot of unused GB. let me repeat, we added 80GB for files cache by decreasing buffers from 64GB to 16GB. there are was 150GB of unused, and now unused part is only 70GB. some of links i read about eviction http://linux-mm.org/PageReplacementDesign http://linux-mm.org/PageReplacementRequirements mikhail