Thread: [HACKERS] ucs_wcwidth vintage
Hi hackers, src/backend/utils/mb/wchar.c contains a ~16 year old wcwidth implementation that originally arrived in commit df4cba68, but the upstream code[1] apparently continued evolving and there have been more Unicode revisions since. It probably doesn't matter much: the observation made by Zr40 in the #postgresql IRC channel that lead me to guess that this code might be responsible is that emojis screw up psql's formatting, since current terminal emulators recognise them as double-width but PostgreSQL doesn't. Still, it's interesting that we have artefacts deriving from various different frozen versions of the Unicode standard in the source tree, and that might affect some proper languages. 🤔 [1] http://www.cl.cam.ac.uk/~mgk25/ucs/wcwidth.c -- Thomas Munro http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Thomas Munro wrote: > Hi hackers, > > src/backend/utils/mb/wchar.c contains a ~16 year old wcwidth > implementation that originally arrived in commit df4cba68, but the > upstream code[1] apparently continued evolving and there have been > more Unicode revisions since. I think we should update it to current upstream source, then, just like we (are supposed to) do for any other piece of code we adopt. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
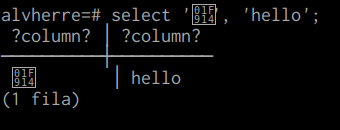
Thomas Munro wrote: > Hi hackers, > > src/backend/utils/mb/wchar.c contains a ~16 year old wcwidth > implementation that originally arrived in commit df4cba68, but the > upstream code[1] apparently continued evolving and there have been > more Unicode revisions since. It probably doesn't matter much: the > observation made by Zr40 in the #postgresql IRC channel that lead me > to guess that this code might be responsible is that emojis screw up > psql's formatting, since current terminal emulators recognise them as > double-width but PostgreSQL doesn't. Still, it's interesting that we > have artefacts deriving from various different frozen versions of the > Unicode standard in the source tree, and that might affect some proper > languages. > > 🤔 Ah, thanks for the test case: alvherre=# select '🤔', 'hello'; ?column? │ ?column? ──────────┼────────── 🤔 │ hello (1 fila) -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
{kind=link}
Alvaro Herrera <alvherre@alvh.no-ip.org> writes:
> Thomas Munro wrote:
>> src/backend/utils/mb/wchar.c contains a ~16 year old wcwidth
>> implementation that originally arrived in commit df4cba68, but the
>> upstream code[1] apparently continued evolving and there have been
>> more Unicode revisions since.
> I think we should update it to current upstream source, then, just like
> we (are supposed to) do for any other piece of code we adopt.
+1 ... also, is that upstream still the best reference?
regards, tom lane
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers