Thread: Re: Error LOG: could not receive data from client: Connection reset by peer
Re: Error LOG: could not receive data from client: Connection reset by peer
by peer.
SQL Error [08006]: An I/O error occurred while sending to the backend.
On Thu, 2023-06-22 at 09:56 +0000, prathap vathuluru wrote: > I am seeing the below error message in My PostgreSQL Error log and My client is unable to connect to Database . > > DB Level Log : > > 2023-06-22 09:30:10 UTC 192.168.0.60(22237) [29452-1] XXXXXX@XXXXXX LOG: could not receive data from client: Connectionreset > by peer. > > Application level Error : > > Wed Jun 21 14:53:18 CEST 2023 > SQL Error [08006]: An I/O error occurred while sending to the backend. > > Could you please , Suggest relevant resolution for the Above issue ., We have 5 databases with enough resources in thesame cluster . Usually, it is a network problem. Try to adjust the TCP keepalive settings: https://www.cybertec-postgresql.com/en/tcp-keepalive-for-a-better-postgresql-experience/ Yours, Laurenz Albe
Different Data Directories For Different Databases In One Instance
Hi @pgsql-admin@lists.postgresql.org ,
I have 2 mounts /data/feed & /data/bets
I have postgres-dev server on which I have 6 feed databases (let’s say a,b,c,d,e,f) and 4 bets databases(lets say g,h,i,j)
I want to group the data directories based on the databases, and they all should be running from the same instance. Can I achieve this ?
Or if not, can you suggest me a work-around to achieve this
Regards,
Phani
Hi @pgsql-admin@lists.postgresql.org ,
I have 2 mounts /data/feed & /data/bets
I have postgres-dev server on which I have 6 feed databases (let’s say a,b,c,d,e,f) and 4 bets databases(lets say g,h,i,j)
I want to group the data directories based on the databases, and they all should be running from the same instance. Can I achieve this ?
Or if not, can you suggest me a work-around to achieve this
Regards,
Phani
Hi @pgsql-admin@lists.postgresql.org ,
I have 2 mounts /data/feed & /data/bets
I have postgres-dev server on which I have 6 feed databases (let’s say a,b,c,d,e,f) and 4 bets databases(lets say g,h,i,j)
I want to group the data directories based on the databases, and they all should be running from the same instance. Can I achieve this ?
Or if not, can you suggest me a work-around to achieve this
Ron Johnson wrote on 4/18/2024 9:09 AM:
On Thu, Apr 18, 2024 at 9:04 AM Phani Prathyush Somayajula <phani.somayajula@pragmaticplay.com> wrote:Hi @pgsql-admin@lists.postgresql.org ,
I have 2 mounts /data/feed & /data/bets
I have postgres-dev server on which I have 6 feed databases (let’s say a,b,c,d,e,f) and 4 bets databases(lets say g,h,i,j)
I want to group the data directories based on the databases, and they all should be running from the same instance. Can I achieve this ?Tablespaces.Or if not, can you suggest me a work-around to achieve this
Symlinks. But tablespaces are the canonical solution.
Regards,
Michael Vitale
703-600-9343

Attachment
Hello All,
I have an AWS RDS instance of type db.m6id.2xlarge ( 8 vCPU and 32 GB RAM)
My Instance specifications are :
Value | |
vCPUs | 8 |
Memory (GiB) | 32 |
Physical Processor | Intel Xeon 8375 |
CPU Architecture | x86 |
Value | |
EBS Optimized | true |
Max Bandwidth (Mbps) on (EBS) | 10000 |
Max Throughput (MB/s) on EBS | 1250.0 |
Max I/O Operations/second (IOPS) | 40000 |
Baseline Bandwidth (Mbps) on (EBS) | 2500 |
Baseline Throughput (MB/s) on EBS | 312.5 |
Baseline I/O Operations/second (IOPS) | 12000 |
Value | |
Network Performance (Gibps) | Up to 12.5 |
Value | |
Generation | current |
Instance Type | db.m6id.2xlarge |
Family | General purpose |
Name | M6ID Double Extra Large |
Normalization Factor | 16 |
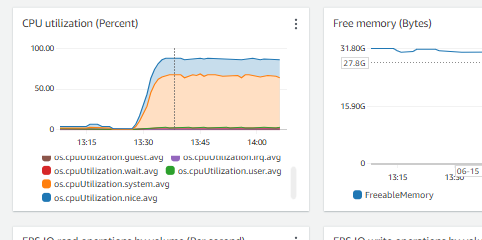
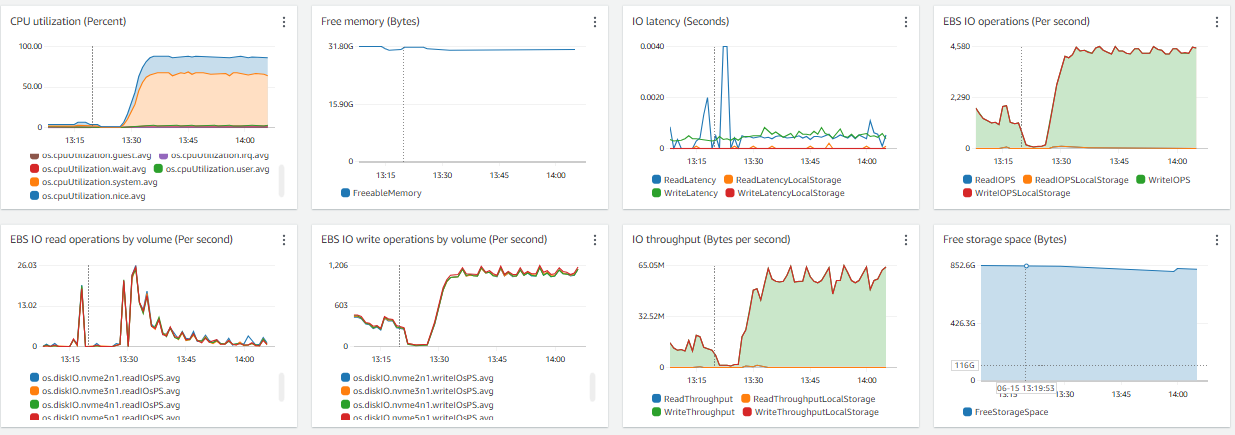
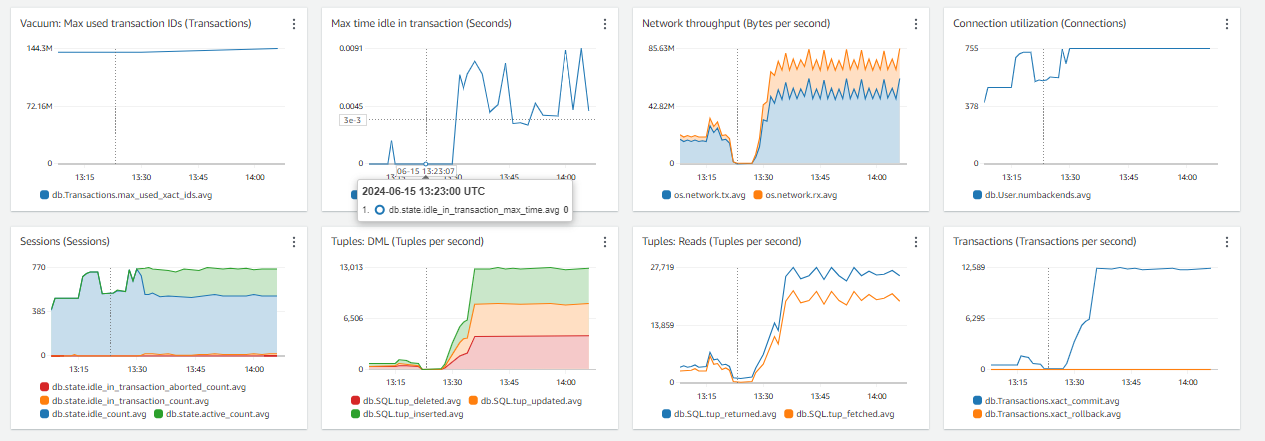
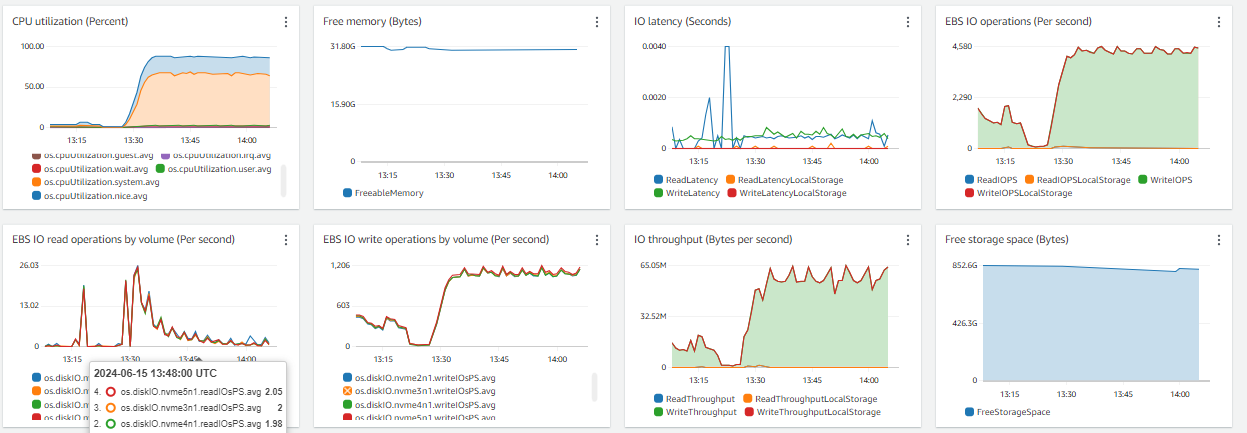
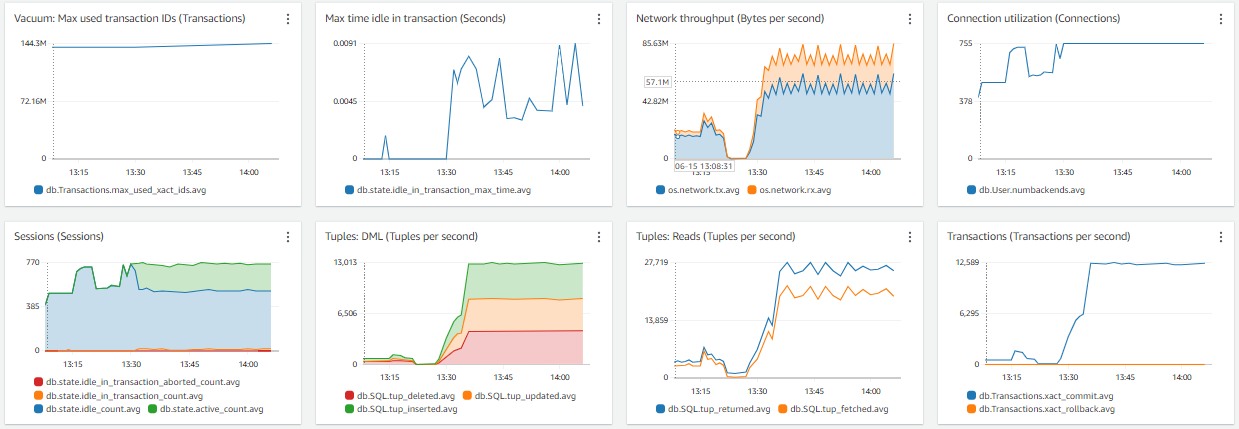
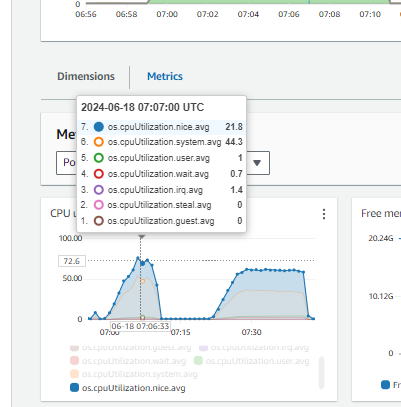
I just want to crosscheck if the parameter that I set are up to the mark. For I’ve verified on couple of portals, and yet the issue is that the CPU consumption is more but not the IOPS, not the EBS throughput / iops
Now I’ll share my issue:
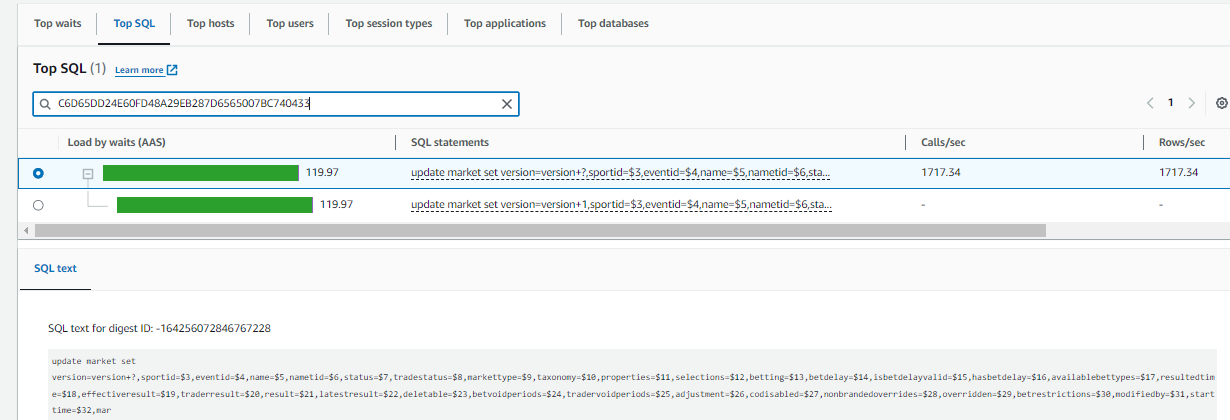
We are seeing a lot of CPU consumption where we’re load testing our application. The query which is taking a lot of time is running less than 1ms if I run through my psql client on the server and is taking 162ms if I run it from dBeaver.
Evidences – attached,
Querry : 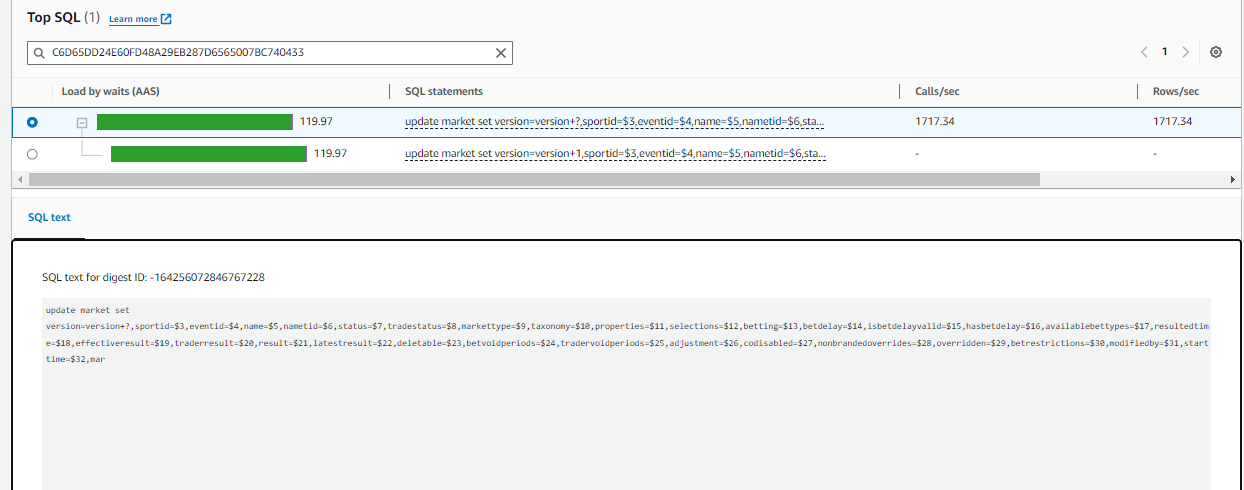
I just want to analyse if the parameters that I set are optimal to the application or not.
Regards,
Phani
Attachment
- image001.png
- Screenshot 2024-06-18 154736.png
- Screenshot 2024-06-15 194023.png
- Screenshot 2024-06-15 194035.png
- Screenshot 2024-06-15 194136.png
- Screenshot 2024-06-15 194239.png
- Screenshot 2024-06-15 194330.png
- Screenshot 2024-06-16 172258.png
- Screenshot 2024-06-18 112503.png
- Screenshot 2024-06-18 152249.png
- Screenshot 2024-06-18 152328.png
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
On Tue, 2024-06-18 at 10:38 +0000, Phani Prathyush Somayajula wrote: > I have an AWS RDS instance > > We are seeing a lot of CPU consumption where we’re load testing our application. > The query which is taking a lot of time is running less than 1ms if I run through > my psql client on the server and is taking 162ms if I run it from dBeaver. > > I just want to analyse if the parameters that I set are optimal to the application or not. I don't think that twiddling the parameters will make a lot of difference there. The exception could be if you are retrieving results with a cursor; then setting "cursor_tuple_fraction" to 1 could make a difference. Other than that, you should use auto_explain with "auto_explain.log_analyze = on" and "auto_explain.log_buffers = on" to capture an execution plan from the slow execution with DBeaver or your application. Examining that plan should show what is going on. Yours, Laurenz Albe
RE: Postgres RDS DB Parameters ::INSTANCE CLASS : db.m6id.2xlarge
Hello @Laurenz, Thank you for your quick response. However, the parameters are already in place as you said. Although, there is no issuewith the update statement. The Execution Plan and the usage of index is optimal for the query. I just want to verifyif any connection pooling is required from database side Regards, Phani -----Original Message----- From: Laurenz Albe <laurenz.albe@cybertec.at> Sent: Tuesday, June 18, 2024 5:11 PM To: Phani Prathyush Somayajula <phani.somayajula@pragmaticplay.com>; pgsql-admin@lists.postgresql.org Subject: Re: Postgres RDS DB Parameters ::INSTANCE CLASS : db.m6id.2xlarge On Tue, 2024-06-18 at 10:38 +0000, Phani Prathyush Somayajula wrote: > I have an AWS RDS instance > > We are seeing a lot of CPU consumption where we’re load testing our application. > The query which is taking a lot of time is running less than 1ms if I > run through my psql client on the server and is taking 162ms if I run it from dBeaver. > > I just want to analyse if the parameters that I set are optimal to the application or not. I don't think that twiddling the parameters will make a lot of difference there. The exception could be if you are retrieving results with a cursor; then setting "cursor_tuple_fraction" to 1 could makea difference. Other than that, you should use auto_explain with "auto_explain.log_analyze = on" and "auto_explain.log_buffers = on" to capture an execution plan from the slow execution with DBeaver or your application. Examining that plan should show what is going on. Yours, Laurenz Albe
Using following url provide PostgreSQL version , type of application ,no CPU memory , max connection , that will calculate parameter , setup like that , re-load the cluster

From: Phani Prathyush Somayajula <phani.somayajula@pragmaticplay.com>
Sent: Tuesday, June 18, 2024 6:38 AM
To: pgsql-admin@lists.postgresql.org
Subject: Postgres RDS DB Parameters ::INSTANCE CLASS : db.m6id.2xlarge
Hello All,
I have an AWS RDS instance of type db.m6id.2xlarge ( 8 vCPU and 32 GB RAM)
My Instance specifications are :
Value | |
vCPUs | 8 |
Memory (GiB) | 32 |
Physical Processor | Intel Xeon 8375 |
CPU Architecture | x86 |
Value | |
EBS Optimized | true |
Max Bandwidth (Mbps) on (EBS) | 10000 |
Max Throughput (MB/s) on EBS | 1250.0 |
Max I/O Operations/second (IOPS) | 40000 |
Baseline Bandwidth (Mbps) on (EBS) | 2500 |
Baseline Throughput (MB/s) on EBS | 312.5 |
Baseline I/O Operations/second (IOPS) | 12000 |
Value | |
Network Performance (Gibps) | Up to 12.5 |
Value | |
Generation | current |
Instance Type | db.m6id.2xlarge |
Family | General purpose |
Name | M6ID Double Extra Large |
Normalization Factor | 16 |
I just want to crosscheck if the parameter that I set are up to the mark. For I’ve verified on couple of portals, and yet the issue is that the CPU consumption is more but not the IOPS, not the EBS throughput / iops
Now I’ll share my issue:
We are seeing a lot of CPU consumption where we’re load testing our application. The query which is taking a lot of time is running less than 1ms if I run through my psql client on the server and is taking 162ms if I run it from dBeaver.
Evidences – attached,
Querry : 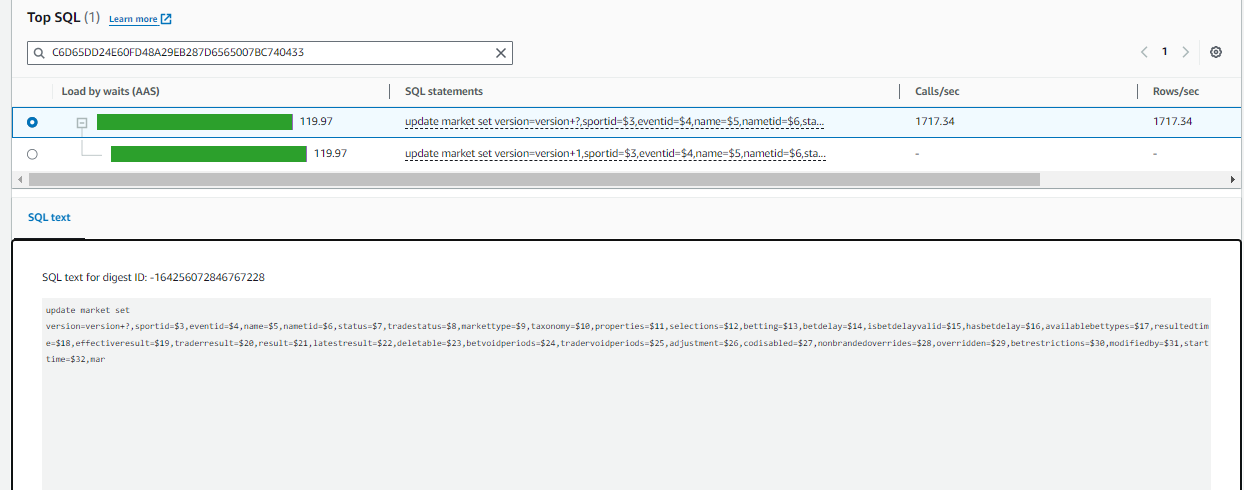
I just want to analyse if the parameters that I set are optimal to the application or not.
Regards,
Phani
Attachment
RE: Postgres RDS DB Parameters ::INSTANCE CLASS : db.m6id.2xlarge
This is awesome. Thanks Lennam
Regards,
Phani
From: lennam@incisivetechgroup.com <lennam@incisivetechgroup.com>
Sent: Tuesday, June 18, 2024 6:53 PM
To: Phani Prathyush Somayajula <phani.somayajula@pragmaticplay.com>; pgsql-admin@lists.postgresql.org
Subject: RE: Postgres RDS DB Parameters ::INSTANCE CLASS : db.m6id.2xlarge
Using following url provide PostgreSQL version , type of application ,no CPU memory , max connection , that will calculate parameter , setup like that , re-load the cluster

From: Phani Prathyush Somayajula <phani.somayajula@pragmaticplay.com>
Sent: Tuesday, June 18, 2024 6:38 AM
To: pgsql-admin@lists.postgresql.org
Subject: Postgres RDS DB Parameters ::INSTANCE CLASS : db.m6id.2xlarge
Hello All,
I have an AWS RDS instance of type db.m6id.2xlarge ( 8 vCPU and 32 GB RAM)
My Instance specifications are :
Value | |
vCPUs | 8 |
Memory (GiB) | 32 |
Physical Processor | Intel Xeon 8375 |
CPU Architecture | x86 |
Value | |
EBS Optimized | true |
Max Bandwidth (Mbps) on (EBS) | 10000 |
Max Throughput (MB/s) on EBS | 1250.0 |
Max I/O Operations/second (IOPS) | 40000 |
Baseline Bandwidth (Mbps) on (EBS) | 2500 |
Baseline Throughput (MB/s) on EBS | 312.5 |
Baseline I/O Operations/second (IOPS) | 12000 |
Value | |
Network Performance (Gibps) | Up to 12.5 |
Value | |
Generation | current |
Instance Type | db.m6id.2xlarge |
Family | General purpose |
Name | M6ID Double Extra Large |
Normalization Factor | 16 |
I just want to crosscheck if the parameter that I set are up to the mark. For I’ve verified on couple of portals, and yet the issue is that the CPU consumption is more but not the IOPS, not the EBS throughput / iops
Now I’ll share my issue:
We are seeing a lot of CPU consumption where we’re load testing our application. The query which is taking a lot of time is running less than 1ms if I run through my psql client on the server and is taking 162ms if I run it from dBeaver.
Evidences – attached,
Querry : 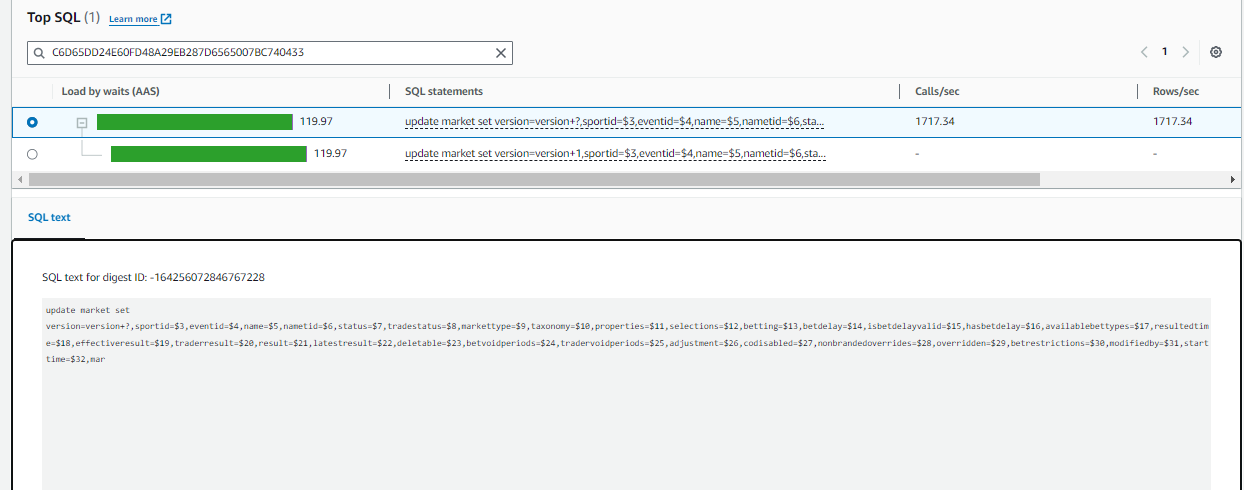
I just want to analyse if the parameters that I set are optimal to the application or not.
Regards,
Phani