Thread: New Window Function: ROW_NUMBER_DESC() OVER() ?
I was working on loans and bank financing, specifically focusing on Amortization Systems. I had the need to reverse the counter for the total number of installments or for a specific set of installments. This "reversal" is essentially a reverse "row_number" function. I realized that it is to "hard work" to write PL/foo functions for this or even to implement it in just SQL using little code.
To streamline the daily process, I conducted a laboratory (prototype, test) using the PostgreSQL 14.3 version doing a small customization. I implemented the window function "row_number_desc," as detailed below.
I would like to assess the feasibility of incorporating this into a future version of Postgres, given its significant utility and practicality in handling bank contract installments in many fields of Finacial Math, because to do use "row_number_desc() over()" is most easy that write a PL/foo or a big lenght SQL string that to do the "descendent case".
What is your opinion regarding this suggestion?
Is it possible to make this a 'feature patch' candidate to PostgreSQL 17?
-------------------------------------------------------------------------------------
/*
int64 curpos = WinGetCurrentPosition(winobj);
Note: In this step, I know that I'll need to use an unused OID returned by the 'src/include/catalog/unused_oids' script.
Note: In this step, I know that I'll need to use an unused OID returned by the 'src/include/catalog/unused_oids' script.
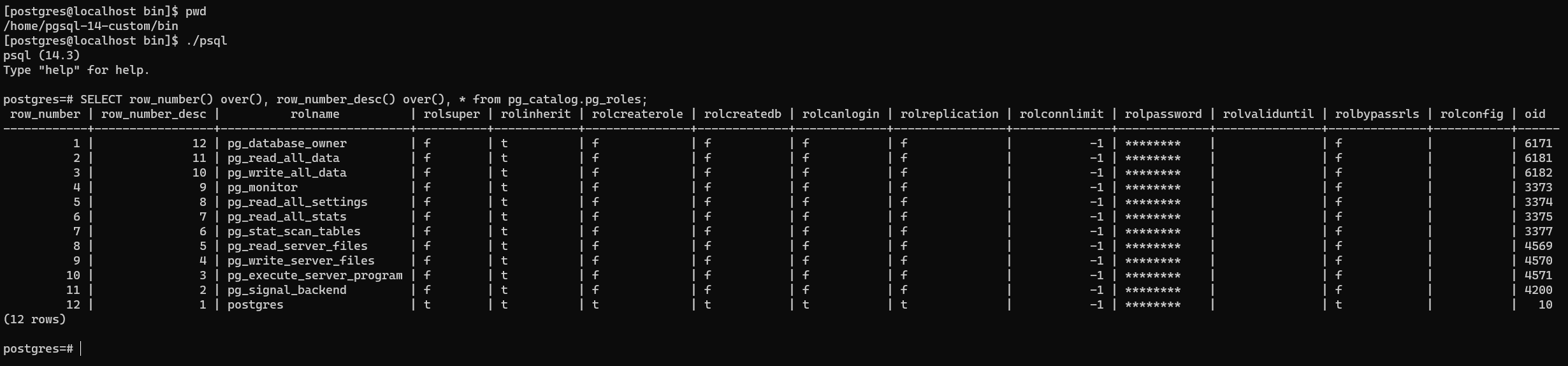
Tks,
Maiquel Orestes Grassi.
Attachment
Hi developers,
I was working on loans and bank financing, specifically focusing on Amortization Systems. I had the need to reverse the counter for the total number of installments or for a specific set of installments. This "reversal" is essentially a reverse "row_number" function. I realized that it is to "hard work" to write PL/foo functions for this or even to implement it in just SQL using little code.
Firstly, I apologize if I wasn't clear in what I intended to propose. I used a very specific example here, and it wasn't very clear what I really wanted to bring up for discussion.
Regards,
Maiquel O. Grassi.
Enviado: terça-feira, 16 de janeiro de 2024 11:30
Para: Maiquel Grassi <grassi@hotmail.com.br>
Cc: pgsql-hackers@postgresql.org <pgsql-hackers@postgresql.org>
Assunto: Re: New Window Function: ROW_NUMBER_DESC() OVER() ?
Hi developers,
I was working on loans and bank financing, specifically focusing on Amortization Systems. I had the need to reverse the counter for the total number of installments or for a specific set of installments. This "reversal" is essentially a reverse "row_number" function. I realized that it is to "hard work" to write PL/foo functions for this or even to implement it in just SQL using little code.
Hello David, how are you?
Firstly, I apologize if I wasn't clear in what I intended to propose. I used a very specific example here, and it wasn't very clear what I really wanted to bring up for discussion.I understand that it's possible to order the "returned dataset" using "order by ... desc."
I don't have a base column to use for "order by," and I also can't use CTID column.
How can I do this without using my reversed enumeration "row_number desc" function?
Count() over() - row_number() over()
But if my dataset is significantly large? Wouldn't calling two window functions instead of one be much slower?
Is count() over() - row_number() over() faster than row_number_desc() over()?
Maiquel.
Hi,
Count() over() - row_number() over()
But if my dataset is significantly large? Wouldn't calling two window functions instead of one be much slower?
Is count() over() - row_number() over() faster than row_number_desc() over()?
---//---
Ok, I'll run the tests to validate these performances and draw some conclusions.
SELECT
row_number() over()
Maiquel.
On 16 Jan 2024, at 16:51, Maiquel Grassi <grassi@hotmail.com.br> wrote:Imagine I have a dataset that is returned to my front-end, and I want to reverse enumerate them (exactly the concept of Math enumerating integers). The row_number does the ascending enumeration, but I need the descending enumeration.
I don't have a base column to use for "order by,"
However, initially, I have one more obstacle in your feedback. If I use count(*) over() - row_number() over(), it gives me an offset of one unit. To resolve this, I need to add 1.This way, simulating a reverse row_number() becomes even more laborious.
I don't have a base column to use for "order by,"
--//--
What I want to do is inverse the enumeration using a simple solution. I want to look at the enumeration of the dataset list from bottom to top, not from top to bottom. I don't want to reverse the sign of the integers. The generated integers in output remain positive.The returned dataset can be from any query. What I need is exactly the opposite of row_number().
Maiquel.
This way, simulating a reverse row_number() becomes even more laborious.
--//--
Maiquel.
However, initially, I have one more obstacle in your feedback. If I use count(*) over() - row_number() over(), it gives me an offset of one unit. To resolve this, I need to add 1.This way, simulating a reverse row_number() becomes even more laborious.I don’t really understand why you think this reverse inserted counting is even a good idea so I don’t really care how laborious it is to implement with existing off-the-shelf tools. A window function named “descending” is non-standard and seemingly non-sensical and should not be added. You can specify order by in the over clause and that is what you should be doing. Mortgage payments are usually monthly, so order by date.David J.
--//--We are just raising hypotheses and discussing healthy possibilities here. This is a suggestion for knowledge and community growth. Note that this is not about a new "feature patch.
I am asking for the community's opinion in general. Your responses are largely appearing aggressive and depreciative. Kindly request you to be more welcoming in your answers and not oppressive. This way, the community progresses more rapidly..
----//----
Thank you for your opinion. We built together one more insight on PostgreSQL for the community.
Best regards,
Maiquel O.
--//--
I performed these three tests(take a look below) quite simple but functional, so that we can get an idea of the performance. Apparently, we have a higher cost in using "count(*) - row_number() + 1" than in using "row_number_desc() over()".
postgres=# select * into public.foo_1 from generate_series(1,1000000);
Regards,
Maiquel.
On Wed, 17 Jan 2024 at 08:51, Michał Kłeczek <michal@kleczek.org> wrote: > I think that’s the main issue: what (semantically) does row_number() mean in that case? You could equally well generaterandom numbers? Well, not quite random as at least row_number() would ensure the number is unique in the result set. The point I think you're trying to make is very valid though. To reinforce that point, here's an example how undefined the behaviour that Maique is relying on: create table t (a int primary key); insert into t values(3),(2),(4),(1),(5); select a,row_number() over() from t; -- Seq Scan a | row_number ---+------------ 3 | 1 2 | 2 4 | 3 1 | 4 5 | 5 set enable_seqscan=0; set enable_bitmapscan=0; select a,row_number() over() from t; -- Index Scan a | row_number ---+------------ 1 | 1 2 | 2 3 | 3 4 | 4 5 | 5 i.e the row numbers are just assigned in whichever order they're given to the WindowAgg node. Maique, As far as I see your proposal, you want to allow something that is undefined to be reversed. I don't think this is a good idea at all. As mentioned by others, you should have ORDER BY clauses and just add a DESC. If you were looking for something to optimize in this rough area, then perhaps adding some kind of "Backward WindowAgg" node (by overloading the existing node) to allow queries such as the following to be executed without an additional sort. SELECT a,row_number() over (order by a desc) from t order by a; The planner complexity is likely fairly easy to implement that. I don't think we'd need to generate any additional Paths. We could invent some pathkeys_contained_in_reverse() function and switch on the Backward flag if it is. The complexity would be in nodeWindowAgg.c... perhaps too much complexity for it to be worthwhile and not add additional overhead to the non-backward case. Or, it might be easier to invent "Backward Materialize" instead and just have the planner use on of those instead of the final sort. David
undefined to be reversed. I don't think this is a good idea at all.
As mentioned by others, you should have ORDER BY clauses and just add
a DESC.
If you were looking for something to optimize in this rough area, then
perhaps adding some kind of "Backward WindowAgg" node (by overloading
the existing node) to allow queries such as the following to be
executed without an additional sort.
SELECT a,row_number() over (order by a desc) from t order by a;
The planner complexity is likely fairly easy to implement that. I
don't think we'd need to generate any additional Paths. We could
invent some pathkeys_contained_in_reverse() function and switch on the
Backward flag if it is.
The complexity would be in nodeWindowAgg.c... perhaps too much
complexity for it to be worthwhile and not add additional overhead to
the non-backward case.
Or, it might be easier to invent "Backward Materialize" instead and
just have the planner use on of those instead of the final sort.
David
undefined to be reversed. I don't think this is a good idea at all.
As mentioned by others, you should have ORDER BY clauses and just add
a DESC.
- Okay, now I'm convinced of that.
If you were looking for something to optimize in this rough area, then
- David, considering this optimization, allowing for that, do you believe it is plausible to try advancing towards a possible Proof of Concept (PoC) implementation?
Maiquel.
On Wed, 17 Jan 2024 at 15:28, Maiquel Grassi <grassi@hotmail.com.br> wrote: > On Wed, 17 Jan 2024 at 14:36, David Rowley <dgrowleyml@gmail.com> wrote: > > If you were looking for something to optimize in this rough area, then > > perhaps adding some kind of "Backward WindowAgg" node (by overloading > > the existing node) to allow queries such as the following to be > > executed without an additional sort. > > > > SELECT a,row_number() over (order by a desc) from t order by a; > > David, considering this optimization, allowing for that, do you believe it is plausible to try advancing towards a possibleProof of Concept (PoC) implementation? I think the largest factor which would influence the success of that would be how much more complex nodeWindowAgg.c would become. There's a couple of good ways to ensure such a patch fails: 1. Copy and paste all the code out of nodeWindowAgg.c and create nodeWindowAggBackward.c and leave a huge maintenance burden. (don't do this) 2. Make nodeWindowAgg.c much more complex and slower by adding dozens of conditions to check if we're in backward mode. I've not taken the time to study nodeWindowAgg.c to know how much more complex supporting reading the tuples backwards would make it. Certainly the use of tuplestore_trim() would have to change and obviously way we read stored tuples back would need to be adjusted. It might just add much more complexity than it would be worth. Part of the work would be finding this out. If making the changes to nodeWindowAgg.c is too complex, then adjusting nodeMaterial.c would at least put us in a better position than having to sort twice. You'd have to add a bool isbackward flag to MaterialPath and then likely add a ScanDirection normal_dir to MaterialState then set "dir" in ExecMaterial() using ScanDirectionCombine of the two scan directions. At least some of what's there would work as a result of that, but likely a few other things in ExecMaterial() would need to be rejiggered. explain.c would need to show "Backward Material", etc. Both cases you'd need to modify planner.c's create_one_window_path() and invent a function such as pathkeys_count_contained_in_backward() or at least pathkeys_contained_in_backward() to detect when you need to use the backward node type. I'd go looking at nodeWindowAgg.c first, if you're interested. David
David Rowley <dgrowleyml@gmail.com> writes:
> On Wed, 17 Jan 2024 at 15:28, Maiquel Grassi <grassi@hotmail.com.br> wrote:
>> On Wed, 17 Jan 2024 at 14:36, David Rowley <dgrowleyml@gmail.com> wrote:
>>> If you were looking for something to optimize in this rough area, then
>>> perhaps adding some kind of "Backward WindowAgg" node (by overloading
>>> the existing node) to allow queries such as the following to be
>>> executed without an additional sort.
>>>
>>> SELECT a,row_number() over (order by a desc) from t order by a;
>> David, considering this optimization, allowing for that, do you believe it is plausible to try advancing towards a
possibleProof of Concept (PoC) implementation?
> I think the largest factor which would influence the success of that
> would be how much more complex nodeWindowAgg.c would become.
Even if a workable patch for that is presented, should we accept it?
I'm having a hard time believing that this requirement is common
enough to justify more than a microscopic addition of complexity.
This whole area is devilishly complicated already, and I can think of
a bunch of improvements that I'd rate as more worthy of developer
effort than this.
regards, tom lane
Even if a workable patch for that is presented, should we accept it?
I'm having a hard time believing that this requirement is common
enough to justify more than a microscopic addition of complexity.
This whole area is devilishly complicated already, and I can think of
a bunch of improvements that I'd rate as more worthy of developer
effort than this.
--//--
Thanks for the advice. I understand that an improvement you consider microscopic may not be worth spending time trying to implement it (considering you are already warning that a good patch might not be accepted). But since you mentioned that you can think of several possible improvements, more worthy of time investment, could you share at least one of them with us that you consider a candidate for an effort?
Regards,
Maiquel.