Thread: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
"zwj"
Date:
Hello,
I found an issue while using the latest version of PG15 (8fa4a1ac61189efffb8b851ee77e1bc87360c445).
I found an issue while using the latest version of PG15 (8fa4a1ac61189efffb8b851ee77e1bc87360c445).
This question is about 'merge into'.
When two merge into statements are executed concurrently, I obtain the following process and results.
Firstly, the execution results of each Oracle are different, and secondly, I tried to understand its execution process and found that it was not very clear.
<merge into & merge into>
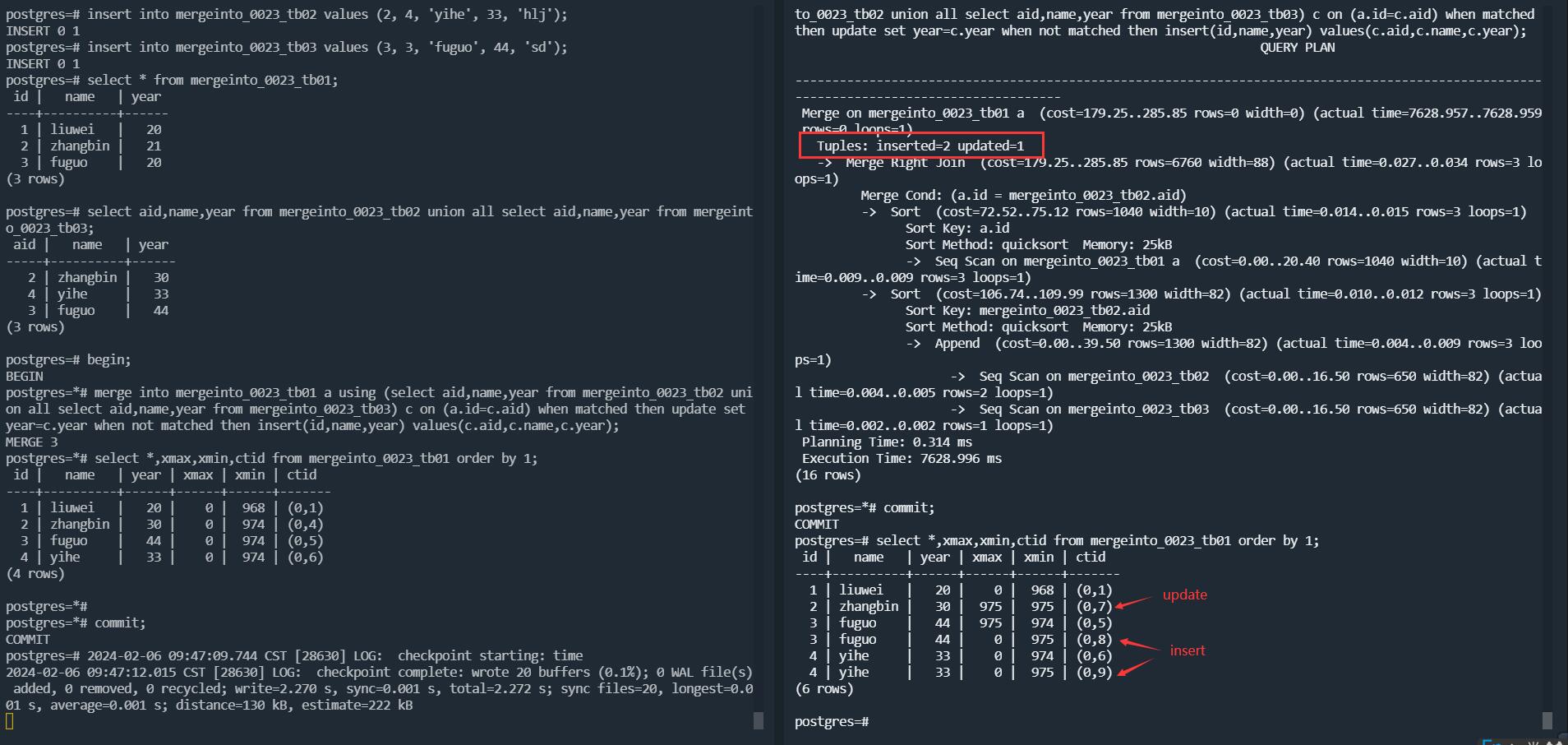
The first merge statement clearly updates the year field for ID 2 and 3, and then inserts the row for ID 4.
But when the second merge statement is executed, the year field of id 2 is actually updated based on the execution of the first merge statement, and then insert rows of id 3 and id 4.
I don't understand, I think if it is updated, it should be that both ID 2 and 3 have been updated.
I am currently unable to determine whether ID 4 should be updated or insert.
According to the results from Oracle, the second merge statement should have updated id 2 3 4.
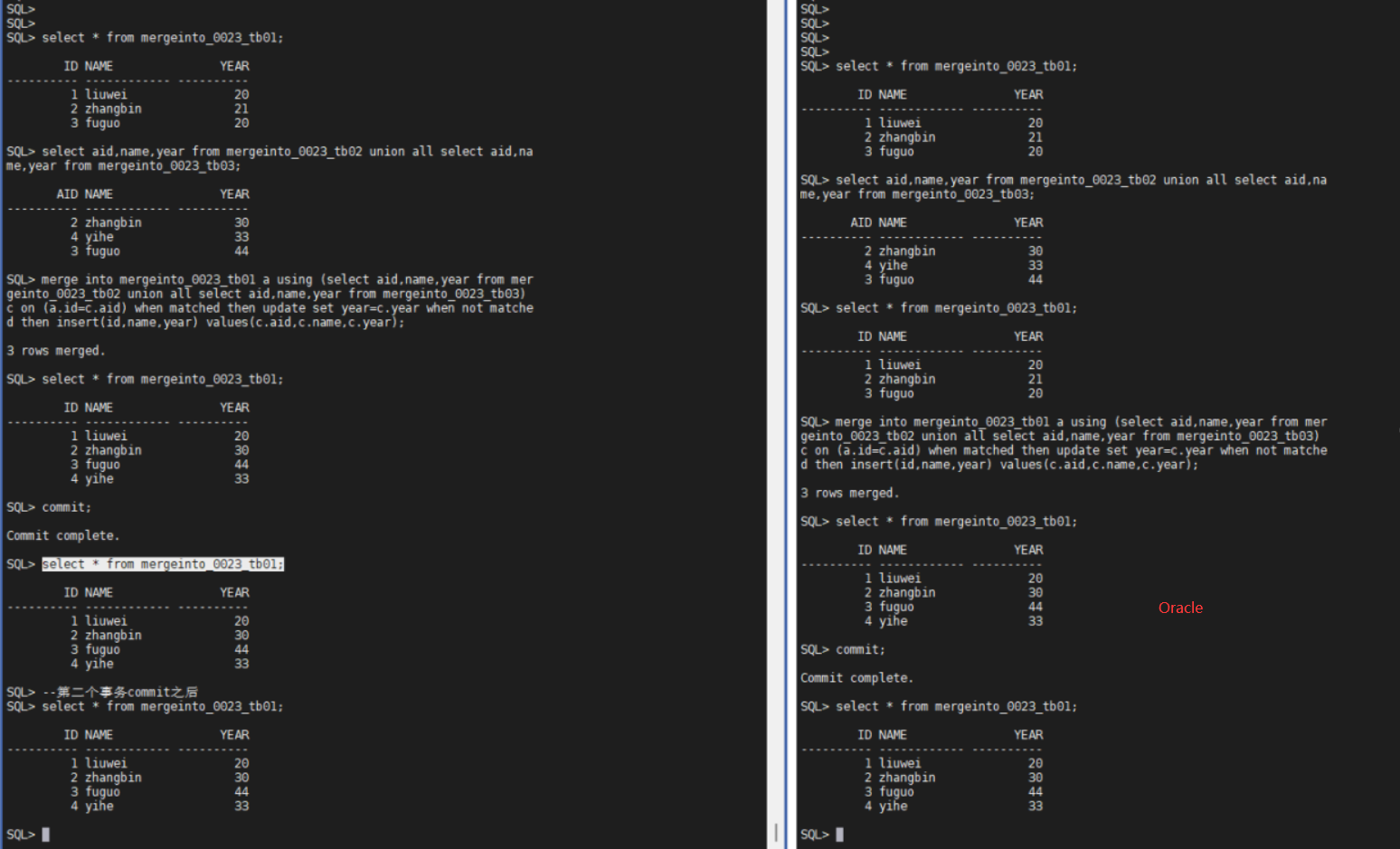
<update & merge into>
I think the problem with the above scenario is due to the concurrent scenarios of update and merge, the behavior of PG and Oracle is consistent. The following figure:
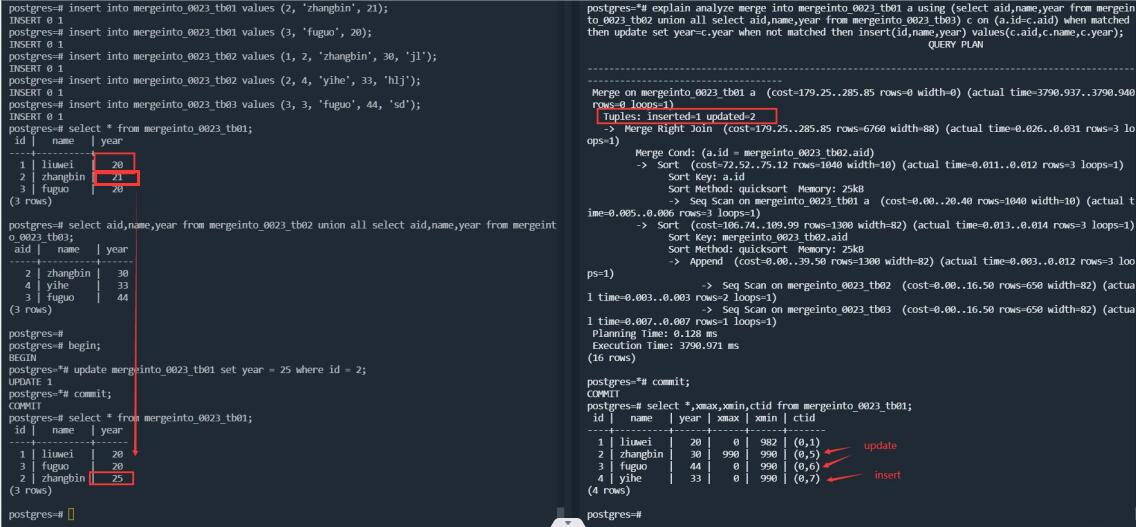
(The results of Oracle and PG are consistent)
In my opinion, in the concurrent scenarios of mergeand merge, the behavior of pg seems inconsistent. Can you help me analyze and take a look, and help us use SQL with clearer semantics?
Looking forward to your reply.
Thanks
wenjiang_zhang
Attachment
Re: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
Dean Rasheed
Date:
On Mon, 19 Feb 2024 at 17:48, zwj <sxzwj@vip.qq.com> wrote:
>
> Hello,
>
> I found an issue while using the latest version of PG15 (8fa4a1ac61189efffb8b851ee77e1bc87360c445).
> This question is about 'merge into'.
>
> When two merge into statements are executed concurrently, I obtain the following process and results.
> Firstly, the execution results of each Oracle are different, and secondly, I tried to understand its execution
processand found that it was not very clear.
>
Hmm, looking at this I think there is a problem with how UNION ALL
subqueries are pulled up, and I don't think it's necessarily limited
to MERGE.
Looking at the plan for this MERGE operation:
explain (verbose, costs off)
merge into mergeinto_0023_tb01 a using (select aid,name,year from
mergeinto_0023_tb02 union all select aid,name,year from
mergeinto_0023_tb03) c on (a.id=c.aid) when matched then update set
year=c.year when not matched then insert(id,name,year)
values(c.aid,c.name,c.year);
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Merge on public.mergeinto_0023_tb01 a
-> Merge Right Join
Output: a.ctid, mergeinto_0023_tb02.year,
mergeinto_0023_tb02.aid, mergeinto_0023_tb02.name,
(ROW(mergeinto_0023_tb02.aid, mergeinto_0023_tb02.name,
mergeinto_0023_tb02.year))
Merge Cond: (a.id = mergeinto_0023_tb02.aid)
-> Sort
Output: a.ctid, a.id
Sort Key: a.id
-> Seq Scan on public.mergeinto_0023_tb01 a
Output: a.ctid, a.id
-> Sort
Output: mergeinto_0023_tb02.year,
mergeinto_0023_tb02.aid, mergeinto_0023_tb02.name,
(ROW(mergeinto_0023_tb02.aid, mergeinto_0023_tb02.name,
mergeinto_0023_tb02.year))
Sort Key: mergeinto_0023_tb02.aid
-> Append
-> Seq Scan on public.mergeinto_0023_tb02
Output: mergeinto_0023_tb02.year,
mergeinto_0023_tb02.aid, mergeinto_0023_tb02.name,
ROW(mergeinto_0023_tb02.aid, mergeinto_0023_tb02.name,
mergeinto_0023_tb02.year)
-> Seq Scan on public.mergeinto_0023_tb03
Output: mergeinto_0023_tb03.year,
mergeinto_0023_tb03.aid, mergeinto_0023_tb03.name,
ROW(mergeinto_0023_tb03.aid, mergeinto_0023_tb03.name,
mergeinto_0023_tb03.year)
The "ROW(...)" targetlist entries are added because
preprocess_rowmarks() adds a rowmark to the UNION ALL subquery, which
at that point is the only non-target relation in the jointree. It does
this intending that the same values be returned during EPQ rechecking.
However, pull_up_subqueries() causes the UNION all subquery and its
leaf subqueries to be pulled up into the main query as appendrel
entries. So when it comes to EPQ rechecking, the rowmark does
absolutely nothing, and EvalPlanQual() does a full re-scan of
mergeinto_0023_tb02 and mergeinto_0023_tb03 and a re-sort for each
concurrently modified row.
A similar thing happens for UPDATE and DELETE, if they're joined to a
UNION ALL subquery. However, AFAICS that doesn't cause a problem
(other than being pretty inefficient) since, for UPDATE and DELETE,
the join to the UNION ALL subquery will always be an inner join, I
think, and so the join output will always be correct.
However, for MERGE, the join may be an outer join, so during an EPQ
recheck, we're joining the target relation (fixed to return just the
updated row) to the full UNION ALL subquery. So if it's an outer join,
the join output will return all-but-one of the subquery rows as not
matched rows in addition to the one matched row that we want, whereas
the EPQ mechanism is expecting the plan to return just one row.
On the face of it, the simplest fix is to tweak is_simple_union_all()
to prevent UNION ALL subquery pullup for MERGE, forcing a
subquery-scan plan. A quick test shows that that fixes the reported
issue.
is_simple_union_all() already has a test for rowmarks, and a comment
saying that locking isn't supported, but since it is called before
preprocess_rowmarks(), it doesn't know that the subquery is about to
be marked.
However, that leaves the question of whether we should do the same for
UPDATE and DELETE. There doesn't appear to be a live bug there, so
maybe they're best left alone. Also, back-patching a change like that
might make existing queries less efficient. But I feel like I might be
overlooking something here, and this doesn't seem to be how EPQ
rechecks are meant to work (doing a full re-scan of non-target
relations). Also, if the concurrent update were an update of a key
column that was included in the join condition, the re-scan would
follow the update to a new matching source row, which is inconsistent
with what would happen if it were a join to a regular relation.
Thoughts?
Regards,
Dean
Re: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
Dean Rasheed
Date:
On Tue, 20 Feb 2024 at 14:49, Dean Rasheed <dean.a.rasheed@gmail.com> wrote: > > Also, if the concurrent update were an update of a key > column that was included in the join condition, the re-scan would > follow the update to a new matching source row, which is inconsistent > with what would happen if it were a join to a regular relation. > In case it wasn't clear what I was talking about there, here's a simple example: -- Setup DROP TABLE IF EXISTS src1, src2, tgt; CREATE TABLE src1 (a int, b text); CREATE TABLE src2 (a int, b text); CREATE TABLE tgt (a int, b text); INSERT INTO src1 SELECT x, 'Src1 '||x FROM generate_series(1, 3) g(x); INSERT INTO src2 SELECT x, 'Src2 '||x FROM generate_series(4, 6) g(x); INSERT INTO tgt SELECT x, 'Tgt '||x FROM generate_series(1, 6, 2) g(x); -- Session 1 BEGIN; UPDATE tgt SET a = 2 WHERE a = 1; -- Session 2 UPDATE tgt t SET b = s.b FROM (SELECT * FROM src1 UNION ALL SELECT * FROM src2) s WHERE s.a = t.a; SELECT * FROM tgt; -- Session 1 COMMIT; and the result in tgt is: a | b ---+-------- 2 | Src1 2 3 | Src1 3 5 | Src2 5 (3 rows) whereas if that UNION ALL subquery had been a regular table with the same contents, the result would have been: a | b ---+-------- 2 | Tgt 1 3 | Src1 3 5 | Src2 5 i.e., the concurrently modified row would not have been updated. Regards, Dean
Re: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
Dean Rasheed
Date:
On Tue, 20 Feb 2024 at 14:49, Dean Rasheed <dean.a.rasheed@gmail.com> wrote: > > On the face of it, the simplest fix is to tweak is_simple_union_all() > to prevent UNION ALL subquery pullup for MERGE, forcing a > subquery-scan plan. A quick test shows that that fixes the reported > issue. > > However, that leaves the question of whether we should do the same for > UPDATE and DELETE. > Attached is a patch that prevents UNION ALL subquery pullup in MERGE only. I've re-used and extended the isolation test cases added by 1d5caec221, since it's clear that replacing the plain source relation in those tests with a UNION ALL subquery that returns the same results should produce the same end result. (Without this patch, the UNION ALL subquery is pulled up, EPQ rechecking fails to re-find the match, and a WHEN NOT MATCHED THEN INSERT action is executed instead, resulting in a primary key violation.) It's still not quite clear whether preventing UNION ALL subquery pullup should also apply to UPDATE and DELETE, but I wasn't able to find any live bug there, so I think they're best left alone. This fixes the reported issue, though it's worth noting that concurrent WHEN NOT MATCHED THEN INSERT actions will still lead to duplicate rows being inserted, which is a limitation that is already documented [1]. [1] https://www.postgresql.org/docs/current/transaction-iso.html Regards, Dean
Attachment
Re: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
Tom Lane
Date:
Dean Rasheed <dean.a.rasheed@gmail.com> writes:
> Attached is a patch that prevents UNION ALL subquery pullup in MERGE only.
I think that this is a band-aid that's just masking an error in the
rowmarking logic: it's not doing the right thing for appendrels
made from UNION ALL subqueries. I've not wrapped my head around
exactly where it's going off the rails, but I feel like this ought
to get fixed somewhere else. Please hold off pushing your patch
for now.
(The test case looks valuable though, thanks for working on that.)
regards, tom lane
Re: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
Tom Lane
Date:
I wrote:
> I think that this is a band-aid that's just masking an error in the
> rowmarking logic: it's not doing the right thing for appendrels
> made from UNION ALL subqueries. I've not wrapped my head around
> exactly where it's going off the rails, but I feel like this ought
> to get fixed somewhere else. Please hold off pushing your patch
> for now.
So after studying this for awhile, I see that the planner is emitting
a PlanRowMark that presumes that the UNION ALL subquery will be
scanned as though it's a base relation; but since we've converted it
to an appendrel, the executor just ignores that rowmark, and the wrong
things happen. I think the really right fix would be to teach the
executor to honor such PlanRowMarks, by getting nodeAppend.c and
nodeMergeAppend.c to perform EPQ row substitution. I wrote a draft
patch for that, attached, and it almost works but not quite. The
trouble is that we're jamming the contents of the row identity Var
created for the rowmark into the output of the Append or MergeAppend,
and it doesn't necessarily match exactly. In the test case you
created, the planner produces targetlists like
Output: src_1.val, src_1.id, ROW(src_1.id, src_1.val)
and as you can see the order of the columns doesn't match.
I can see three ways we might attack that:
1. Persuade the planner to build output tlists that always match
the row identity Var. This seems undesirable, because the planner
might have intentionally elided columns that won't be read by the
upper parts of the plan.
2. Change generation of the ROW() expression so that it lists only
the values we're going to output, in the order we're going to
output them. This would amount to saying that for UNION cases
the "identity" of a row need only consider columns used by the
plan, which feels a little odd but I can't think of a reason why
it wouldn't work. I'm not sure how messy this'd be to implement
though, as the set of columns to be emitted isn't fully determined
until much later than where we currently expand the row identity
Vars into RowExprs.
3. Fix the executor to remap what it gets out of the ROW() into the
order of the subquery tlists. This is probably do-able but I'm
not certain; it may be that the executor hasn't enough info.
We might need to teach the planner to produce a mapping projection
and attach it to the Append node, which carries some ABI risk (but
in the past we've gotten away with adding new fields to the ends
of plan nodes in the back branches). Another objection is that
adding cycles to execution rather than planning might be a poor
tradeoff --- although if we only do the work when EPQ is invoked,
maybe it'd be the best way.
It might be that any of these things is too messy to be considered
for back-patching, and we ought to apply what you did in the
back branches. I'd like a better fix in HEAD though.
regards, tom lane
diff --git a/src/backend/executor/nodeAppend.c b/src/backend/executor/nodeAppend.c
index c7059e7528..113217e607 100644
--- a/src/backend/executor/nodeAppend.c
+++ b/src/backend/executor/nodeAppend.c
@@ -288,8 +288,65 @@ static TupleTableSlot *
ExecAppend(PlanState *pstate)
{
AppendState *node = castNode(AppendState, pstate);
+ EState *estate = node->ps.state;
TupleTableSlot *result;
+ if (estate->es_epq_active != NULL)
+ {
+ /*
+ * We are inside an EvalPlanQual recheck. If there is a relevant
+ * rowmark for the append relation, return the test tuple if one is
+ * available.
+ */
+ EPQState *epqstate = estate->es_epq_active;
+ int scanrelid;
+
+ if (bms_get_singleton_member(castNode(Append, node->ps.plan)->apprelids,
+ &scanrelid))
+ {
+ if (epqstate->relsubs_done[scanrelid - 1])
+ {
+ /*
+ * Return empty slot, as either there is no EPQ tuple for this
+ * rel or we already returned it.
+ */
+ TupleTableSlot *slot = node->ps.ps_ResultTupleSlot;
+
+ return ExecClearTuple(slot);
+ }
+ else if (epqstate->relsubs_slot[scanrelid - 1] != NULL)
+ {
+ /*
+ * Return replacement tuple provided by the EPQ caller.
+ */
+ TupleTableSlot *slot = epqstate->relsubs_slot[scanrelid - 1];
+
+ Assert(epqstate->relsubs_rowmark[scanrelid - 1] == NULL);
+
+ /* Mark to remember that we shouldn't return it again */
+ epqstate->relsubs_done[scanrelid - 1] = true;
+
+ return slot;
+ }
+ else if (epqstate->relsubs_rowmark[scanrelid - 1] != NULL)
+ {
+ /*
+ * Fetch and return replacement tuple using a non-locking
+ * rowmark.
+ */
+ TupleTableSlot *slot = node->ps.ps_ResultTupleSlot;
+
+ /* Mark to remember that we shouldn't return more */
+ epqstate->relsubs_done[scanrelid - 1] = true;
+
+ if (!EvalPlanQualFetchRowMark(epqstate, scanrelid, slot))
+ return NULL;
+
+ return slot;
+ }
+ }
+ }
+
/*
* If this is the first call after Init or ReScan, we need to do the
* initialization work.
@@ -405,6 +462,7 @@ ExecEndAppend(AppendState *node)
void
ExecReScanAppend(AppendState *node)
{
+ EState *estate = node->ps.state;
int nasyncplans = node->as_nasyncplans;
int i;
@@ -443,6 +501,23 @@ ExecReScanAppend(AppendState *node)
ExecReScan(subnode);
}
+ /*
+ * Rescan EvalPlanQual tuple(s) if we're inside an EvalPlanQual recheck.
+ * But don't lose the "blocked" status of blocked target relations.
+ */
+ if (estate->es_epq_active != NULL)
+ {
+ EPQState *epqstate = estate->es_epq_active;
+ int scanrelid;
+
+ if (bms_get_singleton_member(castNode(Append, node->ps.plan)->apprelids,
+ &scanrelid))
+ {
+ epqstate->relsubs_done[scanrelid - 1] =
+ epqstate->relsubs_blocked[scanrelid - 1];
+ }
+ }
+
/* Reset async state */
if (nasyncplans > 0)
{
diff --git a/src/backend/executor/nodeMergeAppend.c b/src/backend/executor/nodeMergeAppend.c
index 0817868452..f2c386b123 100644
--- a/src/backend/executor/nodeMergeAppend.c
+++ b/src/backend/executor/nodeMergeAppend.c
@@ -200,11 +200,68 @@ static TupleTableSlot *
ExecMergeAppend(PlanState *pstate)
{
MergeAppendState *node = castNode(MergeAppendState, pstate);
+ EState *estate = node->ps.state;
TupleTableSlot *result;
SlotNumber i;
CHECK_FOR_INTERRUPTS();
+ if (estate->es_epq_active != NULL)
+ {
+ /*
+ * We are inside an EvalPlanQual recheck. If there is a relevant
+ * rowmark for the append relation, return the test tuple if one is
+ * available.
+ */
+ EPQState *epqstate = estate->es_epq_active;
+ int scanrelid;
+
+ if (bms_get_singleton_member(castNode(MergeAppend, node->ps.plan)->apprelids,
+ &scanrelid))
+ {
+ if (epqstate->relsubs_done[scanrelid - 1])
+ {
+ /*
+ * Return empty slot, as either there is no EPQ tuple for this
+ * rel or we already returned it.
+ */
+ TupleTableSlot *slot = node->ps.ps_ResultTupleSlot;
+
+ return ExecClearTuple(slot);
+ }
+ else if (epqstate->relsubs_slot[scanrelid - 1] != NULL)
+ {
+ /*
+ * Return replacement tuple provided by the EPQ caller.
+ */
+ TupleTableSlot *slot = epqstate->relsubs_slot[scanrelid - 1];
+
+ Assert(epqstate->relsubs_rowmark[scanrelid - 1] == NULL);
+
+ /* Mark to remember that we shouldn't return it again */
+ epqstate->relsubs_done[scanrelid - 1] = true;
+
+ return slot;
+ }
+ else if (epqstate->relsubs_rowmark[scanrelid - 1] != NULL)
+ {
+ /*
+ * Fetch and return replacement tuple using a non-locking
+ * rowmark.
+ */
+ TupleTableSlot *slot = node->ps.ps_ResultTupleSlot;
+
+ /* Mark to remember that we shouldn't return more */
+ epqstate->relsubs_done[scanrelid - 1] = true;
+
+ if (!EvalPlanQualFetchRowMark(epqstate, scanrelid, slot))
+ return NULL;
+
+ return slot;
+ }
+ }
+ }
+
if (!node->ms_initialized)
{
/* Nothing to do if all subplans were pruned */
@@ -339,6 +396,7 @@ ExecEndMergeAppend(MergeAppendState *node)
void
ExecReScanMergeAppend(MergeAppendState *node)
{
+ EState *estate = node->ps.state;
int i;
/*
@@ -372,6 +430,24 @@ ExecReScanMergeAppend(MergeAppendState *node)
if (subnode->chgParam == NULL)
ExecReScan(subnode);
}
+
+ /*
+ * Rescan EvalPlanQual tuple(s) if we're inside an EvalPlanQual recheck.
+ * But don't lose the "blocked" status of blocked target relations.
+ */
+ if (estate->es_epq_active != NULL)
+ {
+ EPQState *epqstate = estate->es_epq_active;
+ int scanrelid;
+
+ if (bms_get_singleton_member(castNode(MergeAppend, node->ps.plan)->apprelids,
+ &scanrelid))
+ {
+ epqstate->relsubs_done[scanrelid - 1] =
+ epqstate->relsubs_blocked[scanrelid - 1];
+ }
+ }
+
binaryheap_reset(node->ms_heap);
node->ms_initialized = false;
}
Re: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
Dean Rasheed
Date:
On Fri, 23 Feb 2024 at 00:12, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > So after studying this for awhile, I see that the planner is emitting > a PlanRowMark that presumes that the UNION ALL subquery will be > scanned as though it's a base relation; but since we've converted it > to an appendrel, the executor just ignores that rowmark, and the wrong > things happen. I think the really right fix would be to teach the > executor to honor such PlanRowMarks, by getting nodeAppend.c and > nodeMergeAppend.c to perform EPQ row substitution. Yes, I agree that's a much better solution, if it can be made to work, though I have been really struggling to see how. > the planner produces targetlists like > > Output: src_1.val, src_1.id, ROW(src_1.id, src_1.val) > > and as you can see the order of the columns doesn't match. > I can see three ways we might attack that: > > 1. Persuade the planner to build output tlists that always match > the row identity Var. > > 2. Change generation of the ROW() expression so that it lists only > the values we're going to output, in the order we're going to > output them. > > 3. Fix the executor to remap what it gets out of the ROW() into the > order of the subquery tlists. This is probably do-able but I'm > not certain; it may be that the executor hasn't enough info. > We might need to teach the planner to produce a mapping projection > and attach it to the Append node, which carries some ABI risk (but > in the past we've gotten away with adding new fields to the ends > of plan nodes in the back branches). Another objection is that > adding cycles to execution rather than planning might be a poor > tradeoff --- although if we only do the work when EPQ is invoked, > maybe it'd be the best way. > Of those, option 3 feels like the best one, though I'm really not sure. I played around with it and convinced myself that the executor doesn't have the information it needs to make it work, but I think all it needs is the Append node's original targetlist, as it is just before it's rewritten by set_dummy_tlist_references(), which rewrites the attribute numbers sequentially. In the original targetlist, all the Vars have the right attribute numbers, so it can be used to build the required projection (I think). Attached is a very rough patch. It seemed better to build the projection in the executor rather than the planner, since then the extra work can be avoided, if EPQ is not invoked. It seems to work (it passes the isolation tests, and I couldn't break it in ad hoc testing), but it definitely needs tidying up, and it's hard to be sure that it's not overlooking something. Regards, Dean
Attachment
Re: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
jian he
Date:
On Tue, Feb 27, 2024 at 8:53 PM Dean Rasheed <dean.a.rasheed@gmail.com> wrote:
>
> Attached is a very rough patch. It seemed better to build the
> projection in the executor rather than the planner, since then the
> extra work can be avoided, if EPQ is not invoked.
>
> It seems to work (it passes the isolation tests, and I couldn't break
> it in ad hoc testing), but it definitely needs tidying up, and it's
> hard to be sure that it's not overlooking something.
>
Hi. minor issues.
In nodeAppend.c, nodeMergeAppend.c
+ if (estate->es_epq_active != NULL)
+ {
+ /*
+ * We are inside an EvalPlanQual recheck. If there is a relevant
+ * rowmark for the append relation, return the test tuple if one is
+ * available.
+ */
+ oldcontext = MemoryContextSwitchTo(estate->es_query_cxt);
+
+ node->as_epq_tupdesc = lookup_rowtype_tupdesc_copy(tupType, tupTypmod);
+
+ ExecAssignExprContext(estate, &node->ps);
+
+ node->ps.ps_ProjInfo =
+ ExecBuildProjectionInfo(castNode(Append, node->ps.plan)->epq_targetlist,
+ node->ps.ps_ExprContext,
+ node->ps.ps_ResultTupleSlot,
+ &node->ps,
+ NULL);
+
+ MemoryContextSwitchTo(oldcontext);
EvalPlanQualStart, EvalPlanQualNext will switch the memory context to
es_query_cxt.
so the memory context switch here is not necessary?
do you think it's sane to change
`ExecAssignExprContext(estate, &node->ps);`
to
`
/* need an expression context to do the projection */
if (node->ps.ps_ExprContext == NULL)
ExecAssignExprContext(estate, &node->ps);
`
?
Re: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
Dean Rasheed
Date:
On Wed, 28 Feb 2024 at 09:16, jian he <jian.universality@gmail.com> wrote: > > + oldcontext = MemoryContextSwitchTo(estate->es_query_cxt); > + > + node->as_epq_tupdesc = lookup_rowtype_tupdesc_copy(tupType, tupTypmod); > + > + ExecAssignExprContext(estate, &node->ps); > + > + node->ps.ps_ProjInfo = > + ExecBuildProjectionInfo(castNode(Append, node->ps.plan)->epq_targetlist, > + > EvalPlanQualStart, EvalPlanQualNext will switch the memory context to > es_query_cxt. > so the memory context switch here is not necessary? > Yes it is necessary. The EvalPlanQual mechanism switches to the epqstate->recheckestate->es_query_cxt memory context, which is not the same as the main query's estate->es_query_cxt (they're different executor states). Most stuff allocated under EvalPlanQual() is intended to be short-lived (just for the duration of that specific EPQ check), whereas this stuff (the TupleDesc and Projection) is intended to last for the duration of the main query, so that it can be reused in later EPQ checks. > do you think it's sane to change > `ExecAssignExprContext(estate, &node->ps);` > to > ` > /* need an expression context to do the projection */ > if (node->ps.ps_ExprContext == NULL) > ExecAssignExprContext(estate, &node->ps); > ` > ? Possibly. More importantly, it should be doing a ResetExprContext() to free any previous stuff before projecting the new row. At this stage, this is just a rough draft patch. There are many things like that and code comments that will need to be improved before it is committable, but for now I'm more concerned with whether it actually works, and if the approach it's taking is sane. I've tried various things and I haven't been able to break it, but I'm still nervous that I might be overlooking something, particularly in relation to what might get added to the targetlist at various stages during planning for different types of query. Regards, Dean
Re: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
jian he
Date:
On Wed, Feb 28, 2024 at 8:11 PM Dean Rasheed <dean.a.rasheed@gmail.com> wrote: > > On Wed, 28 Feb 2024 at 09:16, jian he <jian.universality@gmail.com> wrote: > > > > + oldcontext = MemoryContextSwitchTo(estate->es_query_cxt); > > + > > + node->as_epq_tupdesc = lookup_rowtype_tupdesc_copy(tupType, tupTypmod); > > + > > + ExecAssignExprContext(estate, &node->ps); > > + > > + node->ps.ps_ProjInfo = > > + ExecBuildProjectionInfo(castNode(Append, node->ps.plan)->epq_targetlist, > > + > > EvalPlanQualStart, EvalPlanQualNext will switch the memory context to > > es_query_cxt. > > so the memory context switch here is not necessary? > > > > Yes it is necessary. The EvalPlanQual mechanism switches to the > epqstate->recheckestate->es_query_cxt memory context, which is not the > same as the main query's estate->es_query_cxt (they're different > executor states). Most stuff allocated under EvalPlanQual() is > intended to be short-lived (just for the duration of that specific EPQ > check), whereas this stuff (the TupleDesc and Projection) is intended > to last for the duration of the main query, so that it can be reused > in later EPQ checks. > sorry for the noise. I understand it now. Another small question: for the Append case, we can set/initialize it at create_append_plan, all other elements are initialized there, why we set it at set_append_references. just wondering.
回复: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
"zwj"
Date:
Hi,hackers
I may have discovered another issue in the concurrency scenario of merge, and I am currently not sure if this new issue is related to the previous one.
It seems that it may also be an issue with the EPQ mechanism in the merge scenario?
I will provide this test case, hoping it will be helpful for you to fix related issues in the future.
DROP TABLE IF EXISTS src1, tgt;
CREATE TABLE src1 (a int, b text);
CREATE TABLE tgt (a int, b text);
INSERT INTO src1 SELECT x, 'Src1 '||x FROM generate_series(1, 3) g(x);
INSERT INTO tgt SELECT x, 'Tgt '||x FROM generate_series(1, 6, 2) g(x);
insert into src1 values(3,'src1 33');
CREATE TABLE src1 (a int, b text);
CREATE TABLE tgt (a int, b text);
INSERT INTO src1 SELECT x, 'Src1 '||x FROM generate_series(1, 3) g(x);
INSERT INTO tgt SELECT x, 'Tgt '||x FROM generate_series(1, 6, 2) g(x);
insert into src1 values(3,'src1 33');
If I only execute merge , I will get the following error:
merge into tgt a using src1 c on a.a = c.a when matched then update set b = c.b when not matched then insert (a,b) values(c.a,c.b); -- excute fail
ERROR: MERGE command cannot affect row a second time
HIINT: Ensure that not more than one source row matches any one target row.
ERROR: MERGE command cannot affect row a second time
HIINT: Ensure that not more than one source row matches any one target row.
But when I execute the update and merge concurrently, I will get the following result set.
--session1
begin;
update tgt set b = 'tgt333' where a =3;
--session2
merge into tgt a using src1 c on a.a = c.a when matched then update set b = c.b when not matched then insert (a,b) values(c.a,c.b); -- excute success
--session1
commit;
select * from tgt;
a | b
---+---------
5 | Tgt 5
1 | Src1 1
2 | Src1 2
3 | Src1 3
3 | src1 33
a | b
---+---------
5 | Tgt 5
1 | Src1 1
2 | Src1 2
3 | Src1 3
3 | src1 33
I think even if the tuple with id:3 is udpated, merge should still be able to retrieve new tuples with id:3, and report the same error as above?
Regards,
wenjiang zhang
wenjiang zhang
------------------ 原始邮件 ------------------
发件人: "jian he" <jian.universality@gmail.com>;
发送时间: 2024年2月29日(星期四) 中午11:04
收件人: "Dean Rasheed"<dean.a.rasheed@gmail.com>;
抄送: "Tom Lane"<tgl@sss.pgh.pa.us>;"zwj"<sxzwj@vip.qq.com>;"pgsql-hackers"<pgsql-hackers@lists.postgresql.org>;
主题: Re: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
>
> On Wed, 28 Feb 2024 at 09:16, jian he <jian.universality@gmail.com> wrote:
> >
> > + oldcontext = MemoryContextSwitchTo(estate->es_query_cxt);
> > +
> > + node->as_epq_tupdesc = lookup_rowtype_tupdesc_copy(tupType, tupTypmod);
> > +
> > + ExecAssignExprContext(estate, &node->ps);
> > +
> > + node->ps.ps_ProjInfo =
> > + ExecBuildProjectionInfo(castNode(Append, node->ps.plan)->epq_targetlist,
> > +
> > EvalPlanQualStart, EvalPlanQualNext will switch the memory context to
> > es_query_cxt.
> > so the memory context switch here is not necessary?
> >
>
> Yes it is necessary. The EvalPlanQual mechanism switches to the
> epqstate->recheckestate->es_query_cxt memory context, which is not the
> same as the main query's estate->es_query_cxt (they're different
> executor states). Most stuff allocated under EvalPlanQual() is
> intended to be short-lived (just for the duration of that specific EPQ
> check), whereas this stuff (the TupleDesc and Projection) is intended
> to last for the duration of the main query, so that it can be reused
> in later EPQ checks.
>
sorry for the noise. I understand it now.
Another small question:
for the Append case, we can set/initialize it at create_append_plan,
all other elements are initialized there,
why we set it at set_append_references.
just wondering.
Re: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
Dean Rasheed
Date:
[cc'ing Alvaro]
On Tue, 5 Mar 2024 at 10:04, zwj <sxzwj@vip.qq.com> wrote:
>
> If I only execute merge , I will get the following error:
> merge into tgt a using src1 c on a.a = c.a when matched then update set b = c.b when not matched then insert
(a,b)values(c.a,c.b); -- excute fail
> ERROR: MERGE command cannot affect row a second time
> HIINT: Ensure that not more than one source row matches any one target row.
>
> But when I execute the update and merge concurrently, I will get the following result set.
>
Yes, this should still produce that error, even after a concurrent update.
In the first example without a concurrent update, when we reach the
tgt.a = 3 row the second time, ExecUpdateAct() returns TM_SelfModified
and we do this:
case TM_SelfModified:
/*
* The SQL standard disallows this for MERGE.
*/
if (TransactionIdIsCurrentTransactionId(context->tmfd.xmax))
ereport(ERROR,
(errcode(ERRCODE_CARDINALITY_VIOLATION),
/* translator: %s is a SQL command name */
errmsg("%s command cannot affect row a second time",
"MERGE"),
errhint("Ensure that not more than one source row
matches any one target row.")));
/* This shouldn't happen */
elog(ERROR, "attempted to update or delete invisible tuple");
break;
whereas in the second case, after a concurrent update, ExecUpdateAct()
returns TM_Updated, we attempt to lock the tuple prior to running EPQ,
and table_tuple_lock() returns TM_SelfModified, which does this:
case TM_SelfModified:
/*
* This can be reached when following an update
* chain from a tuple updated by another session,
* reaching a tuple that was already updated in
* this transaction. If previously modified by
* this command, ignore the redundant update,
* otherwise error out.
*
* See also response to TM_SelfModified in
* ExecUpdate().
*/
if (context->tmfd.cmax != estate->es_output_cid)
ereport(ERROR,
(errcode(ERRCODE_TRIGGERED_DATA_CHANGE_VIOLATION),
errmsg("tuple to be updated or deleted
was already modified by an operation triggered by the current
command"),
errhint("Consider using an AFTER trigger
instead of a BEFORE trigger to propagate changes to other rows.")));
return false;
My initial reaction is that neither of those blocks of code is
entirely correct, and that they should both be doing both of those
checks. I.e., something like the attached (which probably needs some
additional test cases).
Regards,
Dean
Attachment
Re: bug report: some issues about pg_15_stable(8fa4a1ac61189efffb8b851ee77e1bc87360c445)
From
Dean Rasheed
Date:
On Tue, 5 Mar 2024 at 13:55, Dean Rasheed <dean.a.rasheed@gmail.com> wrote: > > > If I only execute merge , I will get the following error: > > merge into tgt a using src1 c on a.a = c.a when matched then update set b = c.b when not matched then insert (a,b)values(c.a,c.b); -- excute fail > > ERROR: MERGE command cannot affect row a second time > > HIINT: Ensure that not more than one source row matches any one target row. > > > > But when I execute the update and merge concurrently, I will get the following result set. > > Yes, this should still produce that error, even after a concurrent update. > > My initial reaction is that neither of those blocks of code is > entirely correct, and that they should both be doing both of those > checks. I.e., something like the attached (which probably needs some > additional test cases). > OK, I've pushed and back-patched that fix for this issue, after adding some tests (nice catch, by the way!). That wasn't related to the original issue though, so the problem with UNION ALL still remains to be fixed. The patch from [1] looks promising (for HEAD at least), but it really needs more pairs of eyes on it (bearing in mind that it's just a rough proof-of-concept patch at this stage). [1] https://www.postgresql.org/message-id/CAEZATCVa-mgPuOdgd8%2BYVgOJ4wgJuhT2mJznbj_tmsGAP8hHJw%40mail.gmail.com Regards, Dean